scVelo is a scalable toolkit for RNA velocity analysis in single cells. This function runs an enhanced scVelo workflow on a Seurat object with improved error handling, version compatibility, and modular design.
Usage
RunSCVELO(
srt = NULL,
adata = NULL,
assay_x = "RNA",
layer_x = "counts",
assay_y = c("spliced", "unspliced"),
layer_y = "counts",
group.by = NULL,
linear_reduction = NULL,
nonlinear_reduction = NULL,
basis = NULL,
mode = "stochastic",
fitting_by = "stochastic",
magic_impute = FALSE,
knn = 5,
t = 2,
min_shared_counts = 30,
n_pcs = 30,
n_neighbors = 30,
filter_genes = TRUE,
min_counts = 3,
min_counts_u = 3,
normalize_per_cell = TRUE,
log_transform = TRUE,
use_raw = FALSE,
diff_kinetics = FALSE,
stream_smooth = NULL,
stream_density = 2,
arrow_length = 5,
arrow_size = 5,
arrow_density = 0.5,
denoise = FALSE,
denoise_topn = 3,
kinetics = FALSE,
kinetics_topn = 100,
calculate_velocity_genes = FALSE,
compute_velocity_confidence = TRUE,
compute_velocity_graph = NULL,
compute_terminal_states = FALSE,
compute_pseudotime = FALSE,
compute_paga = FALSE,
top_n = 6,
cores = 1,
palette = "Chinese",
palcolor = NULL,
legend.position = "on data",
show_plot = TRUE,
save_plot = FALSE,
plot_format = c("pdf", "png", "svg"),
plot_dpi = 300,
plot_prefix = "scvelo",
dirpath = "./scvelo",
backend = c("python", "cpp"),
return_seurat = !is.null(srt),
verbose = TRUE
)Arguments
- srt
A Seurat object. Default is
NULL. If provided,adatawill be ignored.- adata
An anndata object. Default is
NULL.- assay_x
Assay to convert as the main data matrix in the anndata object. Default is
"RNA".- layer_x
Layer name for assay_x in the Seurat object. Default is
"counts".- assay_y
Assays to convert as layers in the anndata object. Default is
c("spliced", "unspliced").- layer_y
Layer names for the assay_y in the Seurat object. Default is
"counts".- group.by
Name of one or more meta.data columns to group (color) cells by.
- linear_reduction
The linear dimensionality reduction method to use. Options are
"pca","svd","ica","nmf","mds", or"glmpca". Default is"pca".- nonlinear_reduction
The nonlinear dimensionality reduction method to use. Options are
"umap","umap-naive","tsne","dm","phate","pacmap","trimap","largevis", or"fr". Default is"umap".- basis
The basis to use for reduction, e.g.,
"UMAP".- mode
Velocity estimation models to use. Can be
"deterministic","stochastic", or"dynamical".- fitting_by
Method used to fit gene velocities for dynamical modeling. Default is
"stochastic".- magic_impute
Flag indicating whether to perform magic imputation. Default is
FALSE.- knn
The number of nearest neighbors for
magic.MAGIC. Default is5.- t
Power to which the diffusion operator is powered for
magic.MAGIC. Default is2.Minimum number of counts (both unspliced and spliced) required for a gene. Default is
30.- n_pcs
Number of principal components to use for linear reduction. Default is
30.- n_neighbors
Number of neighbors to use for constructing the KNN graph. Default is
30.- filter_genes
Whether to filter genes based on minimum counts.
- min_counts
Minimum counts for gene filtering.
- min_counts_u
Minimum unspliced counts for gene filtering.
- normalize_per_cell
Whether to normalize counts per cell.
- log_transform
Whether to apply log transformation.
- use_raw
Whether to use raw data for dynamical modeling.
- diff_kinetics
Whether to use differential kinetics.
- stream_smooth
Multiplication factor for scale in Gaussian kernel around grid point.
- stream_density
Controls the closeness of streamlines. When density = 2 (default), the domain is divided into a 60x60 grid, whereas density linearly scales this grid. Each cell in the grid can have, at most, one traversing streamline. Default is
2.- arrow_length
Length of arrows.
- arrow_size
Size of arrows. Default is
5.- arrow_density
Amount of velocities to show.
- denoise
Boolean flag indicating whether to denoise.
- denoise_topn
Number of genes with highest likelihood selected to infer velocity directions.
- kinetics
Boolean flag indicating whether to estimate RNA kinetics.
- kinetics_topn
Number of genes with highest likelihood selected to infer velocity directions.
- calculate_velocity_genes
Boolean flag indicating whether to calculate velocity genes.
- compute_velocity_confidence
Whether to compute velocity confidence metrics.
- compute_velocity_graph
Whether to compute and store the velocity graph for downstream terminal-state or pseudotime calculations. If
NULL, compute the graph only when terminal states or pseudotime are requested.- compute_terminal_states
Whether to compute terminal states (root and end points).
- compute_pseudotime
Whether to compute velocity pseudotime.
- compute_paga
Whether to compute PAGA (Partition-based graph abstraction).
- top_n
The number of top features to plot.
- cores
The number of cores to use for
cellrank.- palette
Color palette name. Available palettes can be found in thisplot::show_palettes. Default is
"Chinese".- palcolor
Custom colors used to create a color palette. Default is
NULL.- legend.position
Position of legend in plots. Can be
"on data","right margin","bottom right", etc. Default is"on data".- show_plot
Whether to show the plot. Default is
FALSE.- save_plot
Whether to save plots to files. Default is
FALSE.- plot_format
Format for saved plots:
"png"(default),"pdf", or"svg".- plot_dpi
Resolution (DPI) for saved plots. Default is
300.- plot_prefix
Prefix for saved plot filenames. Default is "cellrank".
- dirpath
The directory to save the plots. Default is
"./cellrank".- backend
Backend used to compute RNA velocity.
"python"keeps the original scVelo workflow."cpp"uses the package C++ implementation for a stochastic velocity embedding that is compatible with VelocityPlot.- return_seurat
Whether to return a Seurat object instead of an anndata object. Default is
TRUE.- verbose
Whether to print the message. Default is
TRUE.
Examples
data(pancreas_sub)
pancreas_sub <- standard_scop(pancreas_sub)
#> ℹ [2026-07-02 09:49:12] Start standard processing workflow...
#> ℹ [2026-07-02 09:49:13] Checking a list of <Seurat>...
#> ! [2026-07-02 09:49:13] Data 1/1 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:49:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 1/1 of `srt_list`...
#> ℹ [2026-07-02 09:49:13] Perform `FindVariableFeatures()` on 1/1 of `srt_list`...
#> ℹ [2026-07-02 09:49:13] Use the separate HVF from `srt_list`
#> ℹ [2026-07-02 09:49:13] Number of available HVF: 2000
#> ℹ [2026-07-02 09:49:13] Finished check
#> ℹ [2026-07-02 09:49:13] Perform `ScaleData()`
#> ℹ [2026-07-02 09:49:13] Perform pca linear dimension reduction
#> ℹ [2026-07-02 09:49:14] Use stored estimated dimensions 1:23 for Standardpca
#> ℹ [2026-07-02 09:49:14] Perform `Seurat::FindClusters()` with `cluster_algorithm = 'louvain'` and `cluster_resolution = 0.6`
#> ℹ [2026-07-02 09:49:14] Reorder clusters...
#> ℹ [2026-07-02 09:49:14] Skip `log1p()` because `layer = data` is not "counts"
#> ℹ [2026-07-02 09:49:14] Perform umap nonlinear dimension reduction
#> ✔ [2026-07-02 09:49:21] Standard processing workflow completed
pancreas_sub <- RunSCVELO(
pancreas_sub,
assay_x = "RNA",
group.by = "SubCellType",
linear_reduction = "PCA",
nonlinear_reduction = "UMAP",
backend = "cpp"
)
#> ℹ [2026-07-02 09:49:21] Running scanpy-compatible preprocessing (15998 features -> filter + normalize)...
#> ℹ [2026-07-02 09:49:22] Running scVelo "stochastic" mode with `backend = 'cpp'` (10590 features)
#> ✔ [2026-07-02 09:49:25] scVelo "stochastic" mode completed
#> ✔ [2026-07-02 09:49:25] scVelo cpp backend completed
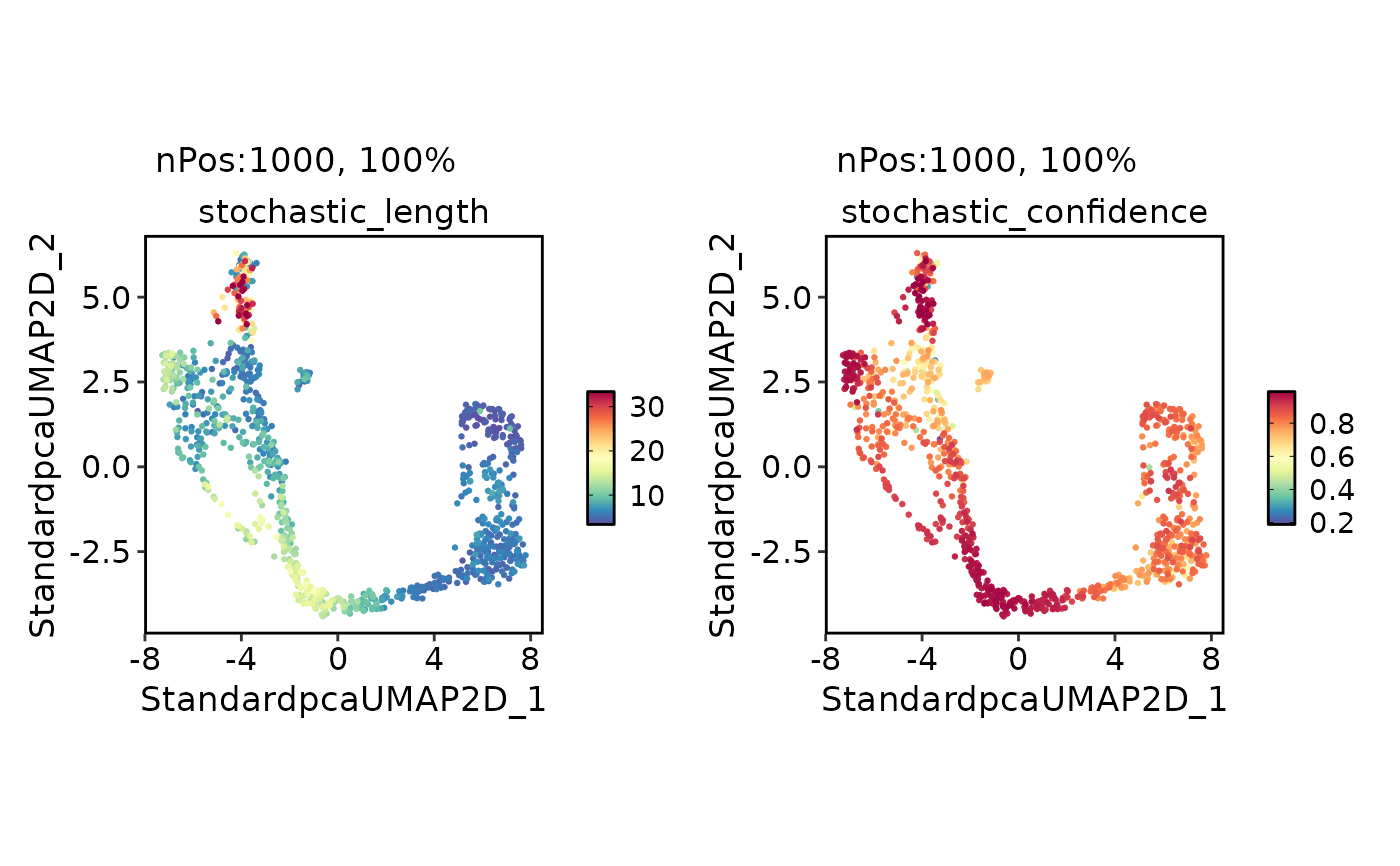
FeatureDimPlot(
pancreas_sub,
c(
"stochastic_length",
"stochastic_confidence"
)
)
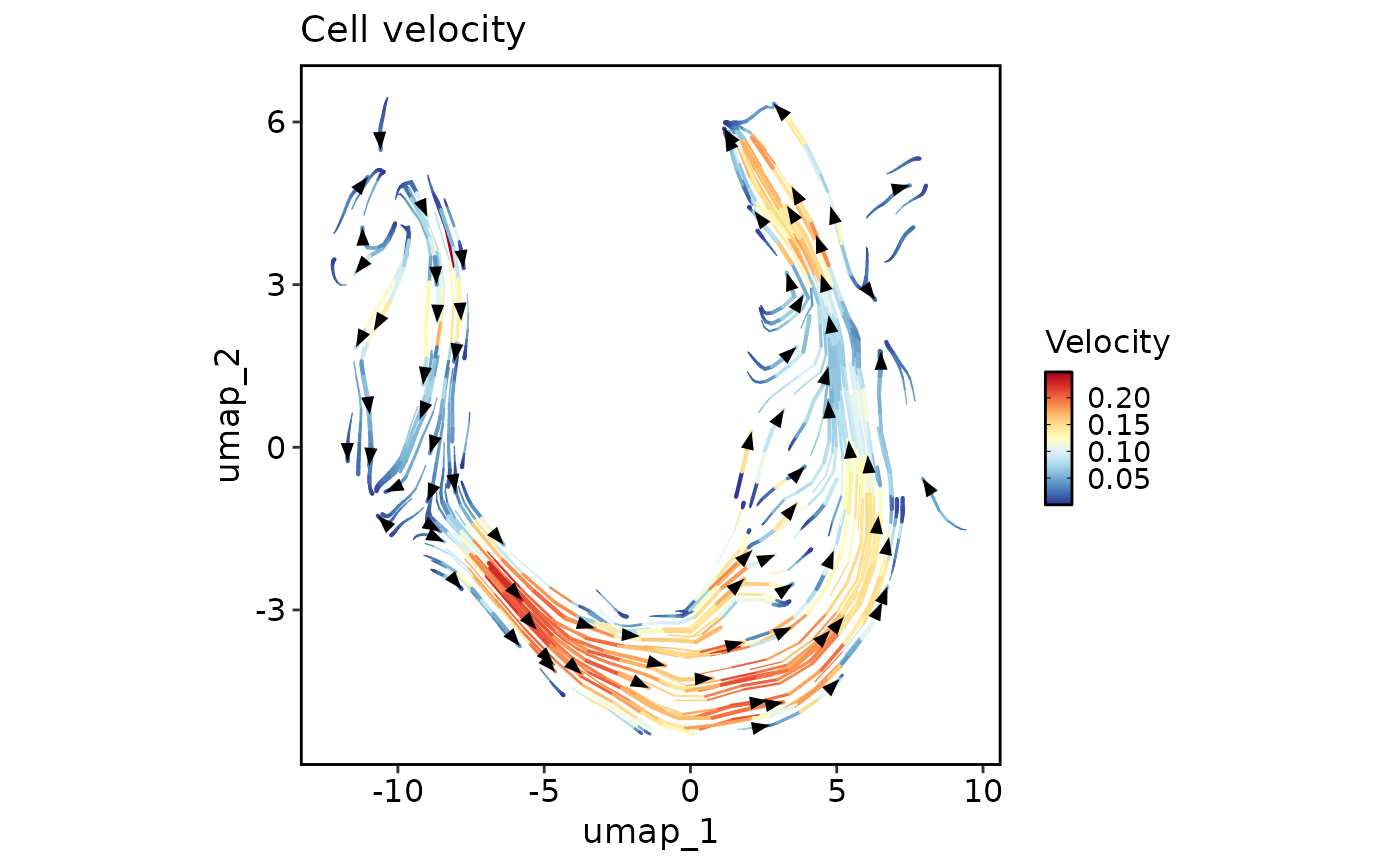
 VelocityPlot(
pancreas_sub,
reduction = "UMAP",
plot_type = "stream"
)
VelocityPlot(
pancreas_sub,
reduction = "UMAP",
plot_type = "stream"
)
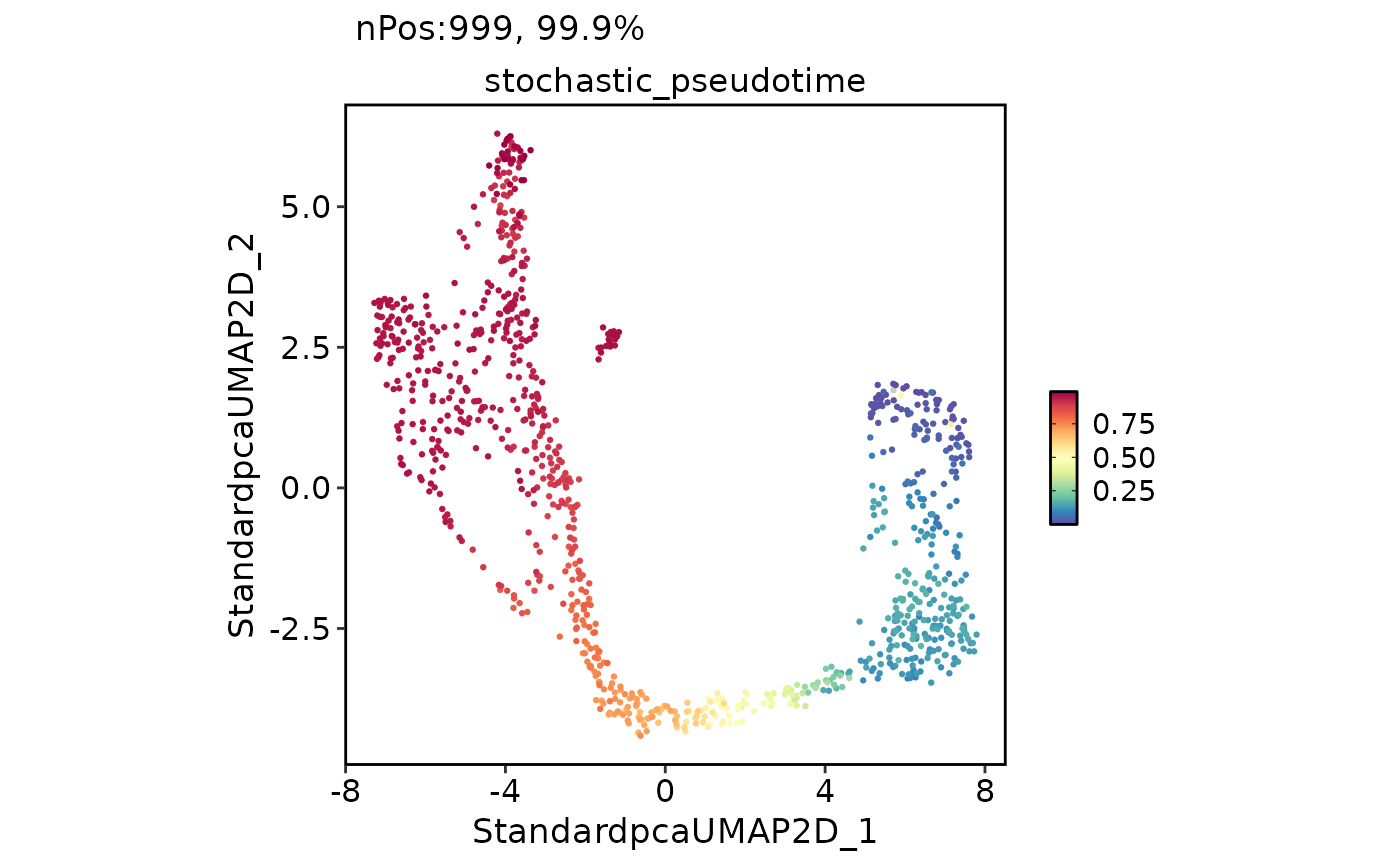 CellDimPlot(
pancreas_sub,
group.by = "SubCellType",
reduction = "UMAP",
pt.size = NA,
velocity = "stochastic"
)
#> Warning: Removed 1000 rows containing missing values or values outside the scale range
#> (`geom_point()`).
#> Warning: Removed 1000 rows containing missing values or values outside the scale range
#> (`geom_point()`).
CellDimPlot(
pancreas_sub,
group.by = "SubCellType",
reduction = "UMAP",
pt.size = NA,
velocity = "stochastic"
)
#> Warning: Removed 1000 rows containing missing values or values outside the scale range
#> (`geom_point()`).
#> Warning: Removed 1000 rows containing missing values or values outside the scale range
#> (`geom_point()`).