This function performs KNN prediction to annotate cell types based on reference scRNA-seq or bulk RNA-seq data.
Usage
RunKNNPredict(
srt_query,
srt_ref = NULL,
bulk_ref = NULL,
query_group = NULL,
ref_group = NULL,
query_assay = NULL,
ref_assay = NULL,
query_reduction = NULL,
ref_reduction = NULL,
query_dims = 1:30,
ref_dims = 1:30,
query_collapsing = !is.null(query_group),
ref_collapsing = TRUE,
return_full_distance_matrix = FALSE,
features = NULL,
features_type = c("HVF", "DE"),
feature_source = "both",
nfeatures = 2000,
DEtest_param = list(max.cells.per.ident = 200, test.use = "wilcox"),
DE_threshold = "p_val_adj < 0.05",
nn_method = NULL,
distance_metric = "cosine",
k = 30,
filter_lowfreq = 0,
prefix = "KNNPredict",
verbose = TRUE
)Arguments
- srt_query
An object of class Seurat to be annotated with cell types.
- srt_ref
An object of class Seurat storing the reference cells.
- bulk_ref
A cell atlas matrix, where cell types are represented by columns and genes are represented by rows. Either
srt_reforbulk_refmust be provided.- query_group
A character vector specifying the column name in the
srt_querymetadata that represents the cell grouping.- ref_group
A character vector specifying the column name in the
srt_refmetadata that represents the cell grouping.- query_assay
A character vector specifying the assay to be used for the query data. Default is the default assay of the
srt_queryobject.- ref_assay
A character vector specifying the assay to be used for the reference data. Default is the default assay of the
srt_refobject.- query_reduction
A character vector specifying the dimensionality reduction method used for the query data. If NULL, the function will use the default reduction method specified in the
srt_queryobject.- ref_reduction
A character vector specifying the dimensionality reduction method used for the reference data. If NULL, the function will use the default reduction method specified in the
srt_refobject.- query_dims
A numeric vector specifying the dimensions to be used for the query data. Default is the first
30dimensions.- ref_dims
A numeric vector specifying the dimensions to be used for the reference data. Default is the first
30dimensions.- query_collapsing
A boolean value indicating whether the query data should be collapsed to group-level average expression values. If TRUE, the function will calculate the average expression values for each group in the query data and the annotation will be performed separately for each group. Otherwise it will use the raw expression values for each cell.
- ref_collapsing
A boolean value indicating whether the reference data should be collapsed to group-level average expression values. If TRUE, the function will calculate the average expression values for each group in the reference data and the annotation will be performed separately for each group. Otherwise it will use the raw expression values for each cell.
- return_full_distance_matrix
A boolean value indicating whether the full distance matrix should be returned. If TRUE, the function will return the distance matrix used for the KNN prediction, otherwise it will only return the annotated cell types.
- features
A character vector specifying the features to be used for the KNN prediction. If
NULL, all the features in the query and reference data will be used.- features_type
A character vector specifying the type of features to be used for the KNN prediction. Must be one of "HVF" (highly variable features) or "DE" (differentially expressed features). Default is
"HVF".- feature_source
The source of the features to be used. Must be one of "both", "query", or "ref". Default is
"both".- nfeatures
An integer specifying the maximum number of features to be used for the KNN prediction. Default is
2000.- DEtest_param
A list of parameters to be passed to the differential expression test function if
features_typeis set to "DE". Default islist(max.cells.per.ident = 200, test.use = "wilcox").- DE_threshold
Threshold used to filter the DE features. If using "roc" test,
DE_thresholdshould be needs to be reassigned. e.g. "power > 0.5". Default is"p_val < 0.05".- nn_method
A character string specifying the nearest neighbor search method to use. Options are "raw", "annoy", and "rann". If "raw" is selected, the function will use the brute-force method to find the nearest neighbors. If "annoy" is selected, the function will use the Annoy library for approximate nearest neighbor search. If "rann" is selected, the function will use the RANN library for approximate nearest neighbor search. If not provided, the function will choose the search method based on the size of the query and reference datasets.
- distance_metric
A character vector specifying the distance metric to be used for calculating similarity between cells. Must be one of "cosine", "euclidean", "manhattan", or "hamming". Default is
"cosine".- k
A number of nearest neighbors to be considered for the KNN prediction. Default is
30.- filter_lowfreq
An integer specifying the threshold for filtering low-frequency cell types from the predicted results. Cell types with a frequency lower than
filter_lowfreqwill be labelled as "unreliable". Default is0, which means no filtering will be performed.- prefix
A character vector specifying the prefix to be added to the resulting annotations. Default is
"KNNPredict".- verbose
Whether to print the message. Default is
TRUE.
Examples
# Annotate cells using bulk RNA-seq data
data(pancreas_sub)
data(ref_scMCA)
pancreas_sub <- standard_scop(pancreas_sub)
#> ℹ [2026-07-02 09:44:00] Start standard processing workflow...
#> ℹ [2026-07-02 09:44:01] Checking a list of <Seurat>...
#> ! [2026-07-02 09:44:01] Data 1/1 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:01] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 1/1 of `srt_list`...
#> ℹ [2026-07-02 09:44:01] Perform `FindVariableFeatures()` on 1/1 of `srt_list`...
#> ℹ [2026-07-02 09:44:01] Use the separate HVF from `srt_list`
#> ℹ [2026-07-02 09:44:02] Number of available HVF: 2000
#> ℹ [2026-07-02 09:44:02] Finished check
#> ℹ [2026-07-02 09:44:02] Perform `ScaleData()`
#> ℹ [2026-07-02 09:44:02] Perform pca linear dimension reduction
#> ℹ [2026-07-02 09:44:02] Use stored estimated dimensions 1:23 for Standardpca
#> ℹ [2026-07-02 09:44:03] Perform `Seurat::FindClusters()` with `cluster_algorithm = 'louvain'` and `cluster_resolution = 0.6`
#> ℹ [2026-07-02 09:44:03] Reorder clusters...
#> ℹ [2026-07-02 09:44:03] Skip `log1p()` because `layer = data` is not "counts"
#> ℹ [2026-07-02 09:44:03] Perform umap nonlinear dimension reduction
#> ✔ [2026-07-02 09:44:09] Standard processing workflow completed
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
bulk_ref = ref_scMCA
)
#> ℹ [2026-07-02 09:44:10] Use [1] 549 features to calculate distance.
#> ℹ [2026-07-02 09:44:10] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:10] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:10] Calculate similarity...
#> ℹ [2026-07-02 09:44:10] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:10] Predict cell type...
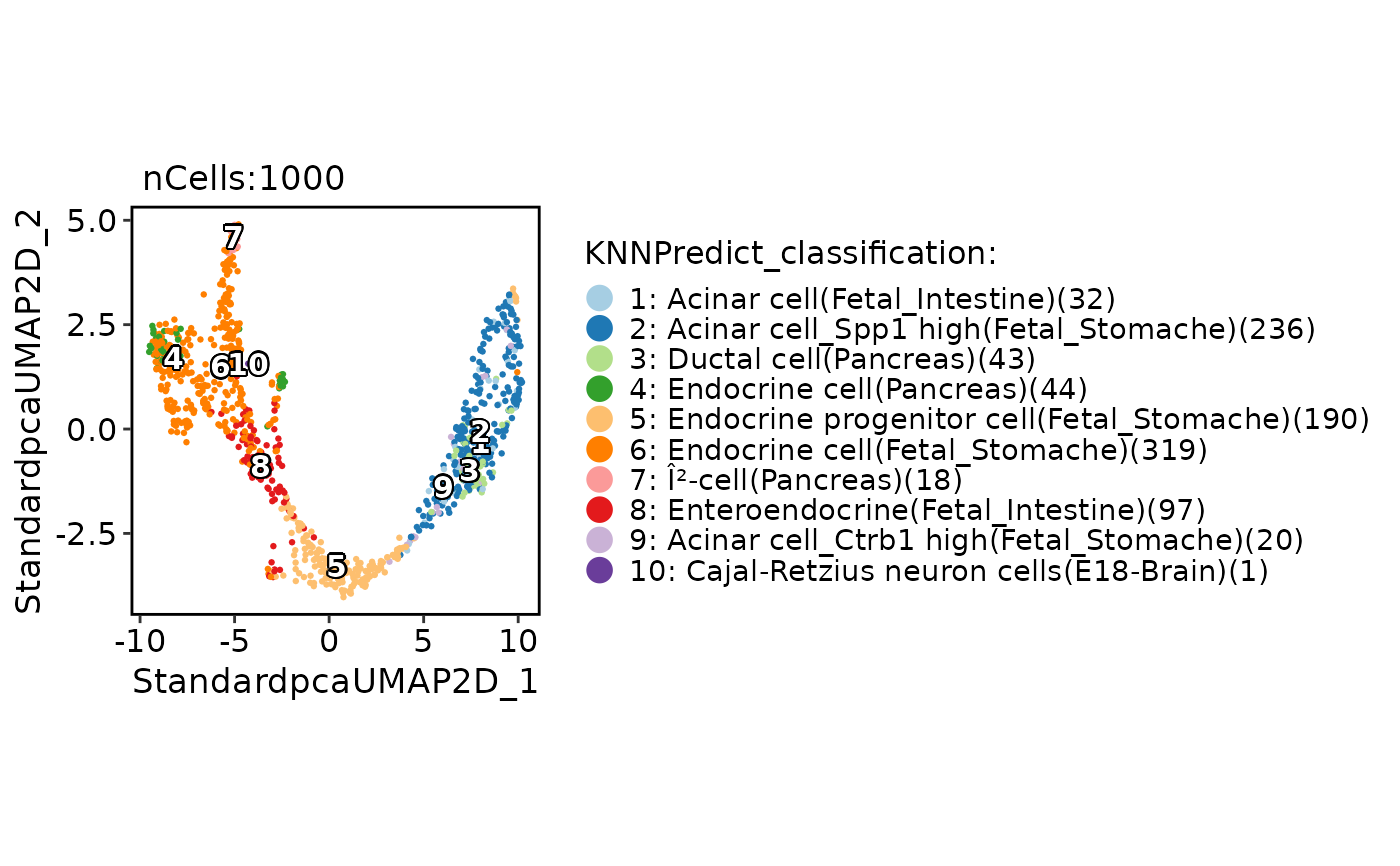
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
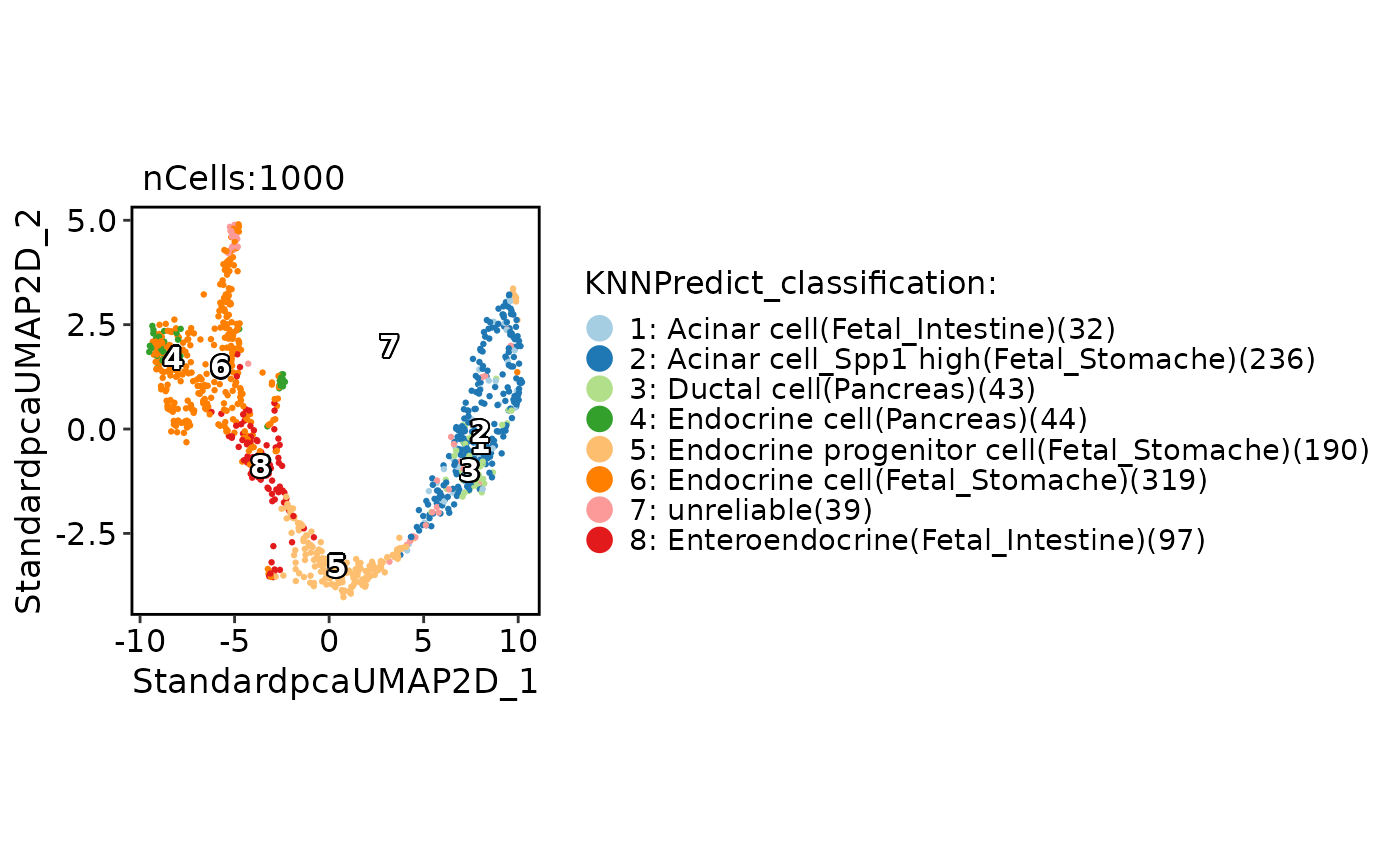
 # Removal of low credible cell types from the predicted results
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
bulk_ref = ref_scMCA,
filter_lowfreq = 30
)
#> ℹ [2026-07-02 09:44:10] Use [1] 549 features to calculate distance.
#> ℹ [2026-07-02 09:44:10] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:10] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:10] Calculate similarity...
#> ℹ [2026-07-02 09:44:10] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:11] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
# Removal of low credible cell types from the predicted results
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
bulk_ref = ref_scMCA,
filter_lowfreq = 30
)
#> ℹ [2026-07-02 09:44:10] Use [1] 549 features to calculate distance.
#> ℹ [2026-07-02 09:44:10] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:10] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:10] Calculate similarity...
#> ℹ [2026-07-02 09:44:10] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:11] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
 # Annotate clusters using bulk RNA-seq data
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
query_group = "SubCellType",
bulk_ref = ref_scMCA
)
#> ℹ [2026-07-02 09:44:11] Use [1] 549 features to calculate distance.
#> ℹ [2026-07-02 09:44:11] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:11] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:11] Calculate similarity...
#> ℹ [2026-07-02 09:44:11] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:11] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
# Annotate clusters using bulk RNA-seq data
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
query_group = "SubCellType",
bulk_ref = ref_scMCA
)
#> ℹ [2026-07-02 09:44:11] Use [1] 549 features to calculate distance.
#> ℹ [2026-07-02 09:44:11] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:11] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:11] Calculate similarity...
#> ℹ [2026-07-02 09:44:11] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:11] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
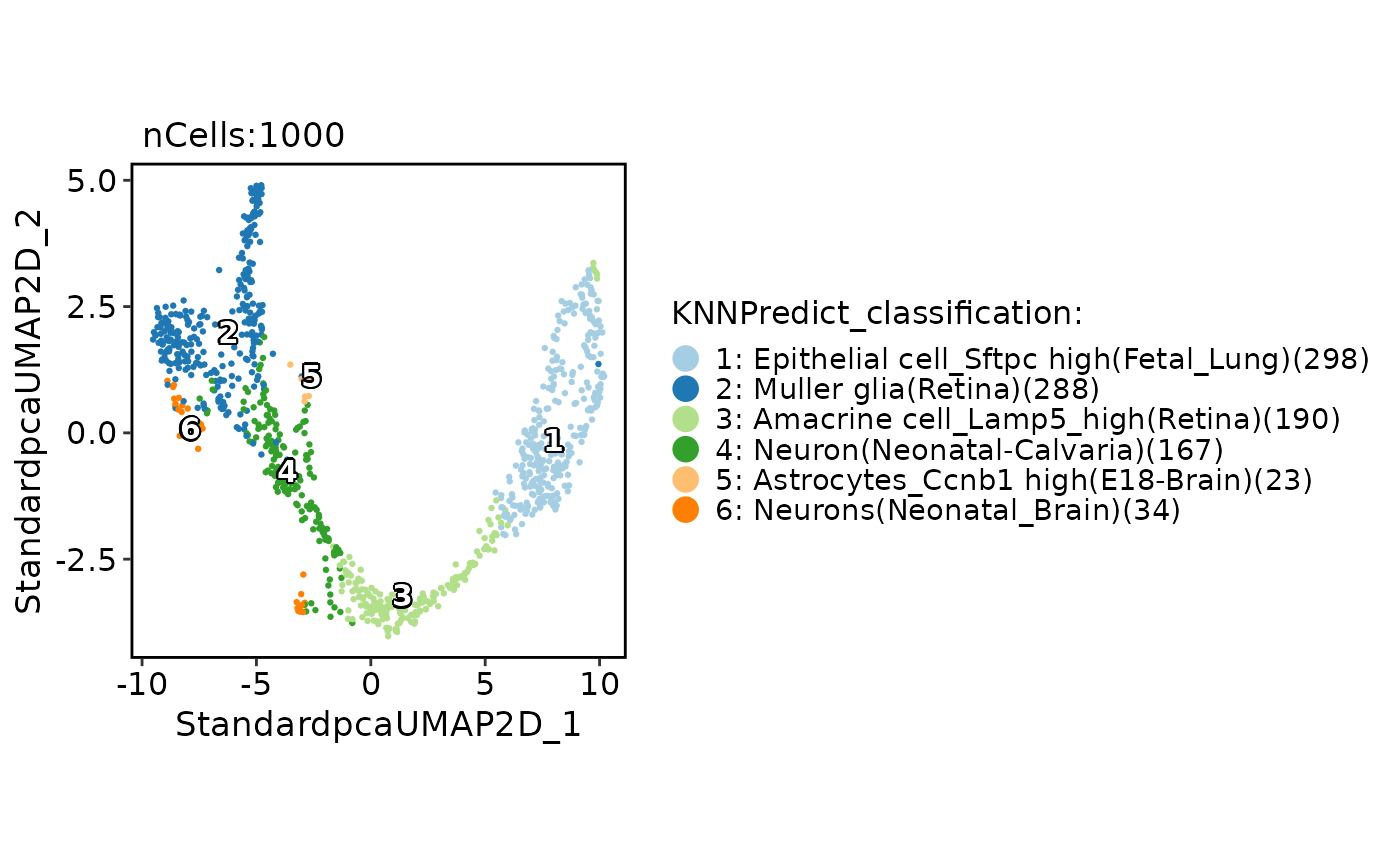 # Annotate using single cell RNA-seq data
data(panc8_sub)
# Simply convert genes from human to mouse and preprocess the data
genenames <- make.unique(
thisutils::capitalize(
rownames(panc8_sub),
force_tolower = TRUE
)
)
names(genenames) <- rownames(panc8_sub)
panc8_sub <- RenameFeatures(
panc8_sub,
newnames = genenames
)
#> ℹ [2026-07-02 09:44:12] Rename features for the assay: RNA
panc8_sub <- CheckDataMerge(
panc8_sub,
batch = "tech"
)[["srt_merge"]]
#> ℹ [2026-07-02 09:44:12] Split `srt_merge` into `srt_list` by "tech"
#> ℹ [2026-07-02 09:44:13] Checking a list of <Seurat>...
#> ! [2026-07-02 09:44:13] Data 1/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 1/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 1/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 2/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 2/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 2/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 3/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 3/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 3/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 4/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 4/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 4/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 5/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 5/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 5/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Use the separate HVF from `srt_list`
#> ℹ [2026-07-02 09:44:14] Number of available HVF: 2000
#> ℹ [2026-07-02 09:44:14] Finished check
panc8_sub <- SeuratObject::JoinLayers(panc8_sub)
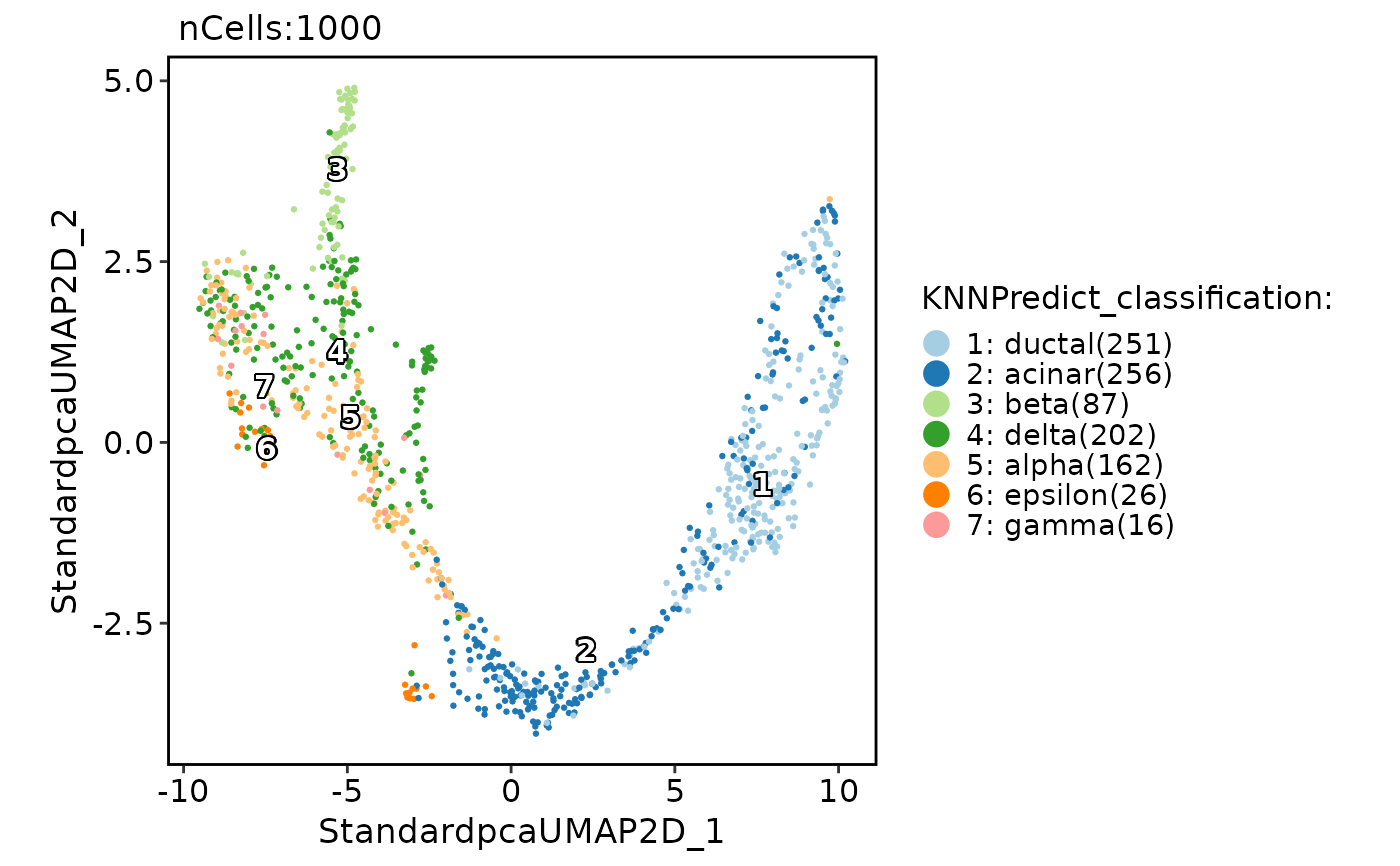
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
ref_group = "celltype"
)
#> ℹ [2026-07-02 09:44:16] Use the HVF to calculate distance metric
#> ℹ [2026-07-02 09:44:16] Use [1] 632 features to calculate distance.
#> ℹ [2026-07-02 09:44:17] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:17] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:17] Calculate similarity...
#> ℹ [2026-07-02 09:44:17] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:17] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
# Annotate using single cell RNA-seq data
data(panc8_sub)
# Simply convert genes from human to mouse and preprocess the data
genenames <- make.unique(
thisutils::capitalize(
rownames(panc8_sub),
force_tolower = TRUE
)
)
names(genenames) <- rownames(panc8_sub)
panc8_sub <- RenameFeatures(
panc8_sub,
newnames = genenames
)
#> ℹ [2026-07-02 09:44:12] Rename features for the assay: RNA
panc8_sub <- CheckDataMerge(
panc8_sub,
batch = "tech"
)[["srt_merge"]]
#> ℹ [2026-07-02 09:44:12] Split `srt_merge` into `srt_list` by "tech"
#> ℹ [2026-07-02 09:44:13] Checking a list of <Seurat>...
#> ! [2026-07-02 09:44:13] Data 1/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 1/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 1/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 2/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 2/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 2/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 3/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 3/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 3/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 4/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 4/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 4/5 of `srt_list`...
#> ! [2026-07-02 09:44:13] Data 5/5 of the `srt_list` is "unknown"
#> ℹ [2026-07-02 09:44:13] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 5/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Perform `FindVariableFeatures()` on 5/5 of `srt_list`...
#> ℹ [2026-07-02 09:44:13] Use the separate HVF from `srt_list`
#> ℹ [2026-07-02 09:44:14] Number of available HVF: 2000
#> ℹ [2026-07-02 09:44:14] Finished check
panc8_sub <- SeuratObject::JoinLayers(panc8_sub)
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
ref_group = "celltype"
)
#> ℹ [2026-07-02 09:44:16] Use the HVF to calculate distance metric
#> ℹ [2026-07-02 09:44:16] Use [1] 632 features to calculate distance.
#> ℹ [2026-07-02 09:44:17] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:17] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:17] Calculate similarity...
#> ℹ [2026-07-02 09:44:17] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:17] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
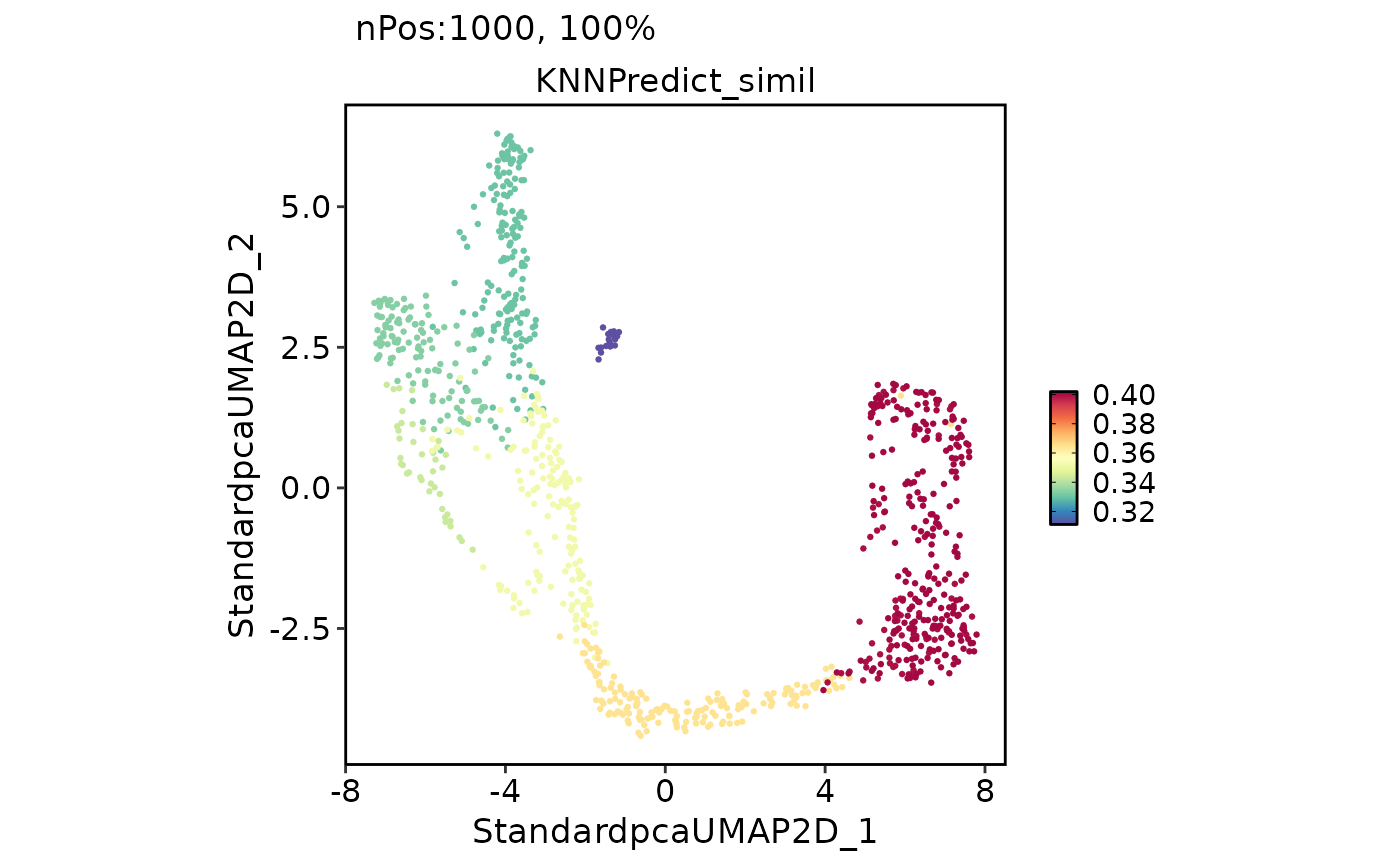
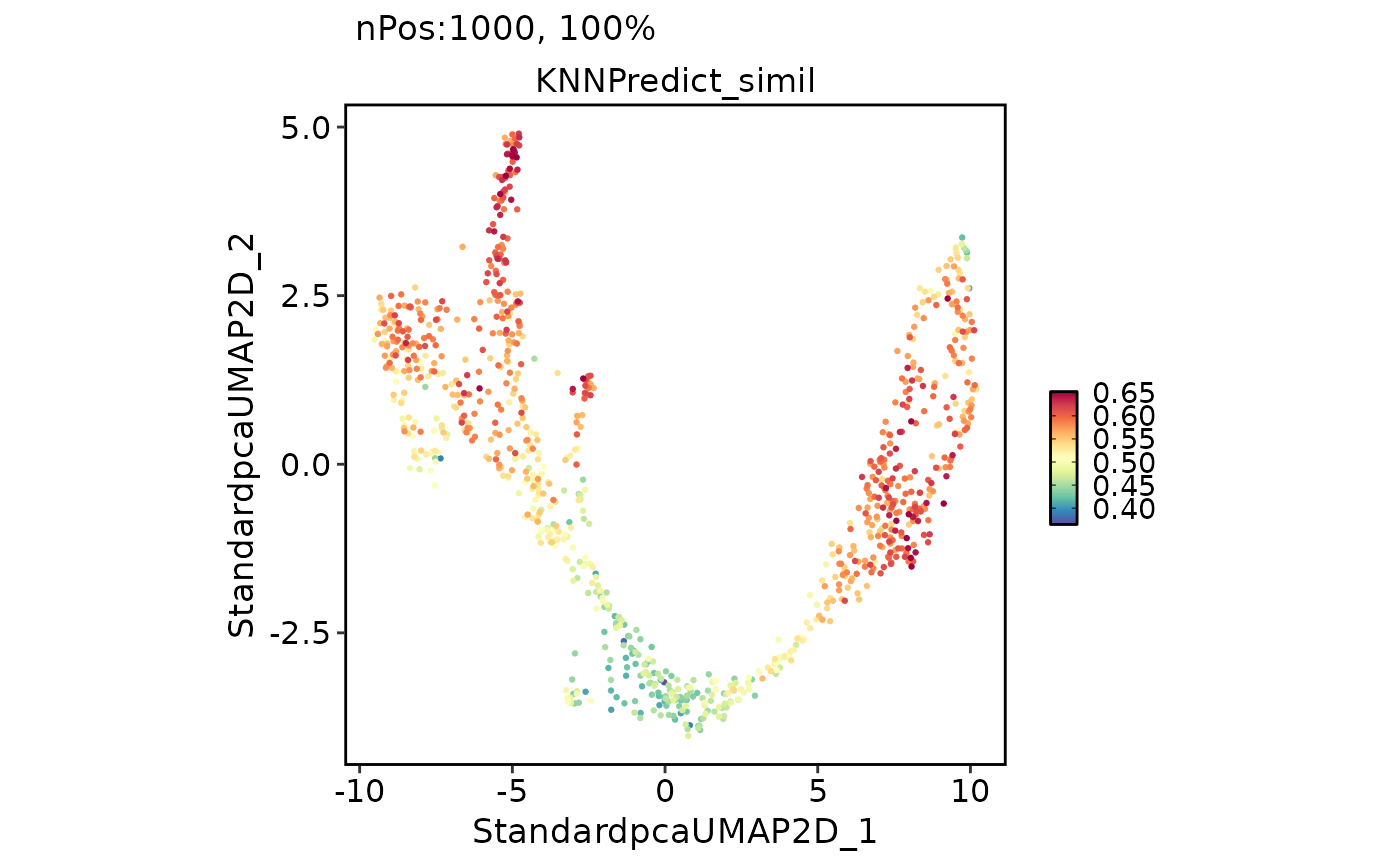
 FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
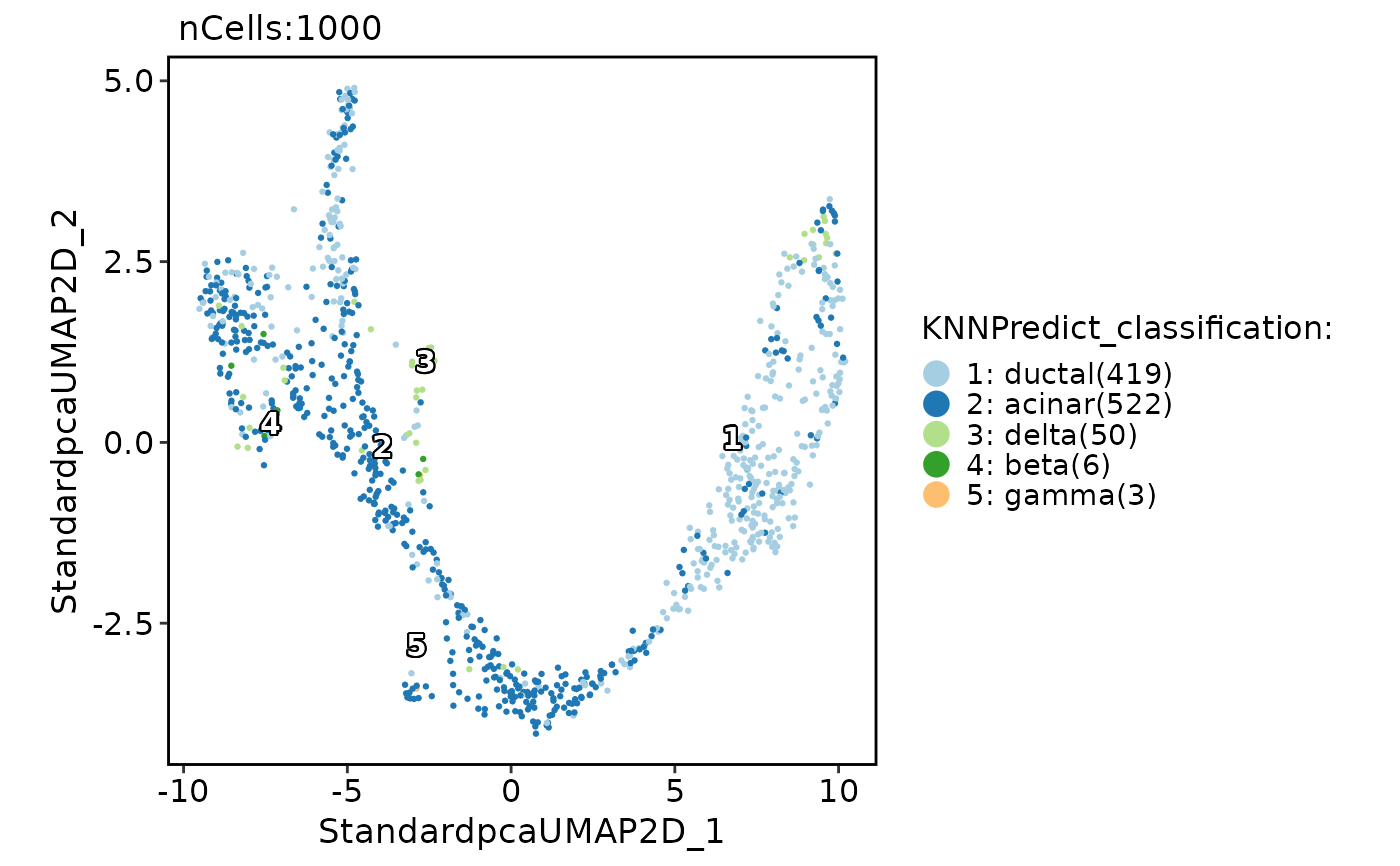
 pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
ref_group = "celltype",
ref_collapsing = FALSE
)
#> ℹ [2026-07-02 09:44:17] Use the HVF to calculate distance metric
#> ℹ [2026-07-02 09:44:17] Use [1] 632 features to calculate distance.
#> ℹ [2026-07-02 09:44:17] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:18] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:18] Calculate similarity...
#> ℹ [2026-07-02 09:44:18] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:18] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
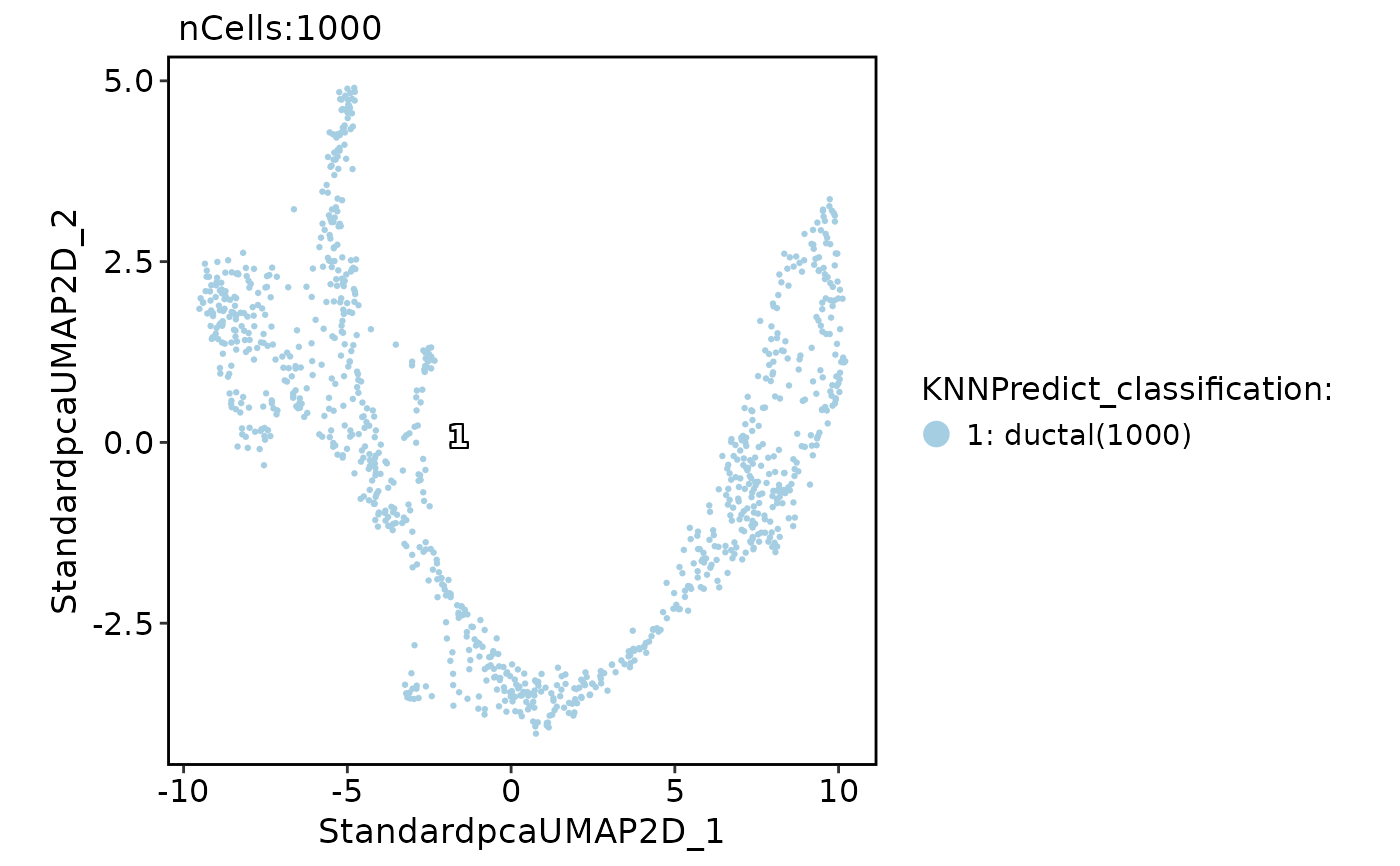
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
ref_group = "celltype",
ref_collapsing = FALSE
)
#> ℹ [2026-07-02 09:44:17] Use the HVF to calculate distance metric
#> ℹ [2026-07-02 09:44:17] Use [1] 632 features to calculate distance.
#> ℹ [2026-07-02 09:44:17] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:18] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:18] Calculate similarity...
#> ℹ [2026-07-02 09:44:18] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:18] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
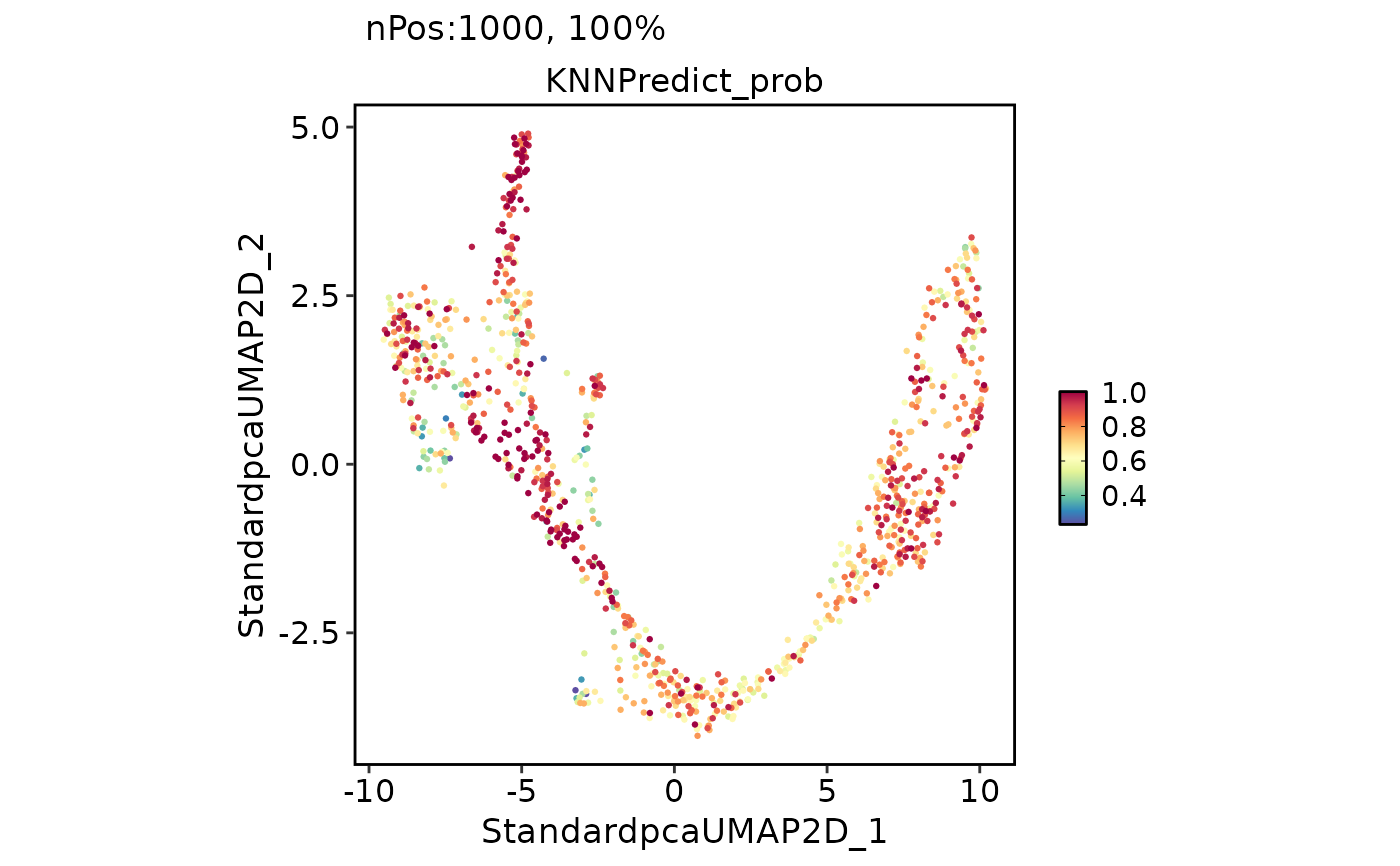
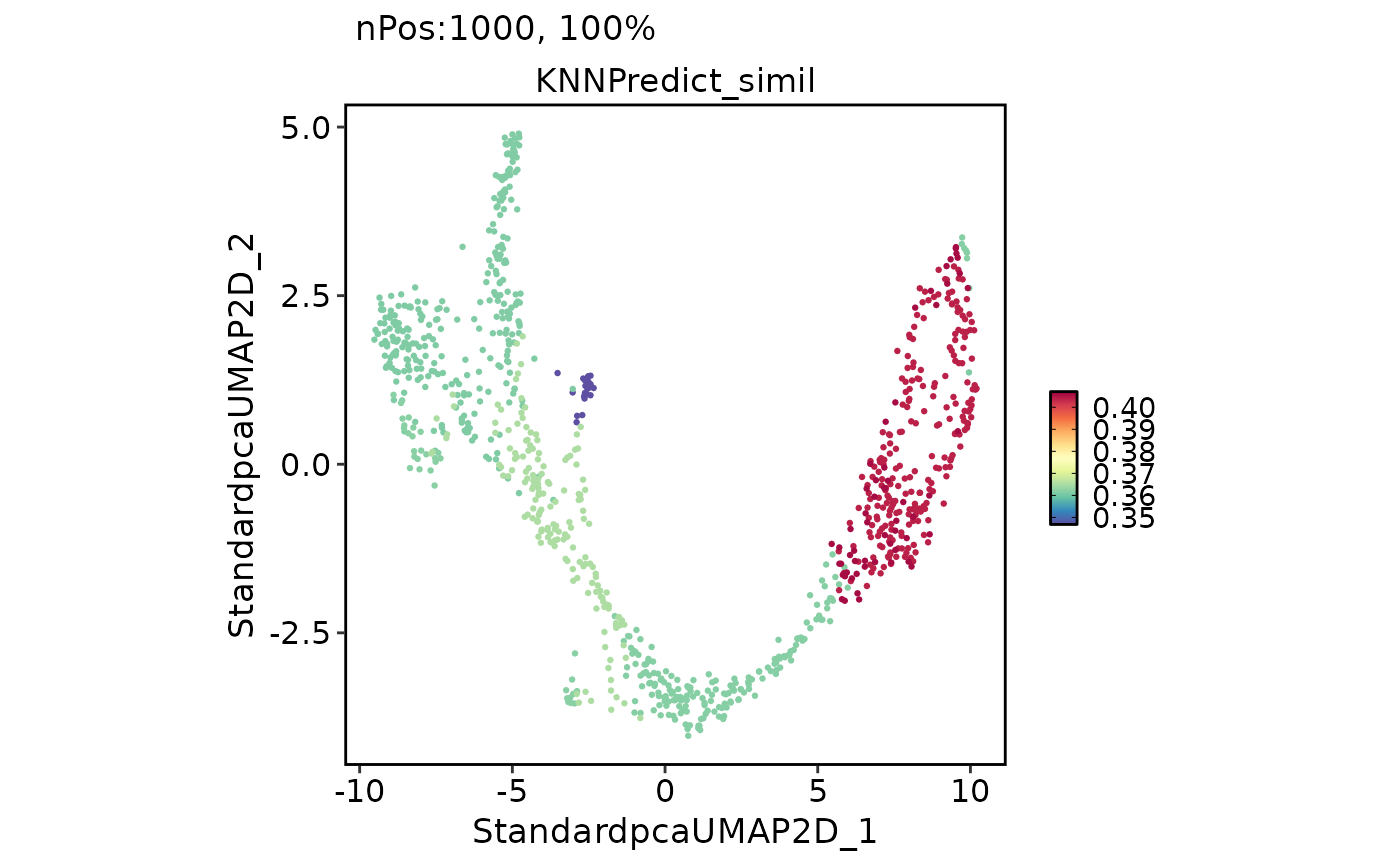
 FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_prob"
)
FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_prob"
)
 pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
query_group = "SubCellType",
ref_group = "celltype"
)
#> ℹ [2026-07-02 09:44:19] Use the HVF to calculate distance metric
#> ℹ [2026-07-02 09:44:19] Use [1] 632 features to calculate distance.
#> ℹ [2026-07-02 09:44:19] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:19] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:19] Calculate similarity...
#> ℹ [2026-07-02 09:44:19] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:19] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
query_group = "SubCellType",
ref_group = "celltype"
)
#> ℹ [2026-07-02 09:44:19] Use the HVF to calculate distance metric
#> ℹ [2026-07-02 09:44:19] Use [1] 632 features to calculate distance.
#> ℹ [2026-07-02 09:44:19] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:19] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:19] Calculate similarity...
#> ℹ [2026-07-02 09:44:19] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:19] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
 FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
 # Annotate with DE gene instead of HVF
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
ref_group = "celltype",
features_type = "DE",
feature_source = "ref",
DEtest_param = list(cores = 2)
)
#> ℹ [2026-07-02 09:44:20] Data type is log-normalized
#> ℹ [2026-07-02 09:44:20] Start differential expression test
#> ℹ [2026-07-02 09:44:20] Find all markers(wilcox) among [1] 13 groups...
#> ℹ [2026-07-02 09:44:20] Using 2 cores
#> ⠙ [2026-07-02 09:44:20] Running for delta [1/13] 8% | ETA: 7s
#> ⠹ [2026-07-02 09:44:20] Running for activated-stellate [6/13] ■■■■ 46% |…
#> ✔ [2026-07-02 09:44:20] Completed 13 tasks in 4.7s
#>
#> ℹ [2026-07-02 09:44:20] Building results
#> ✔ [2026-07-02 09:44:25] Differential expression test completed
#> ℹ [2026-07-02 09:44:25] Use the DE features from AllMarkers_wilcox to calculate distance metric.
#> ℹ [2026-07-02 09:44:25] DE features number of the ref data: [1] 1998
#> ℹ [2026-07-02 09:44:25] Use [1] 1998 features to calculate distance.
#> ℹ [2026-07-02 09:44:25] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:25] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:25] Calculate similarity...
#> ℹ [2026-07-02 09:44:25] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:25] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
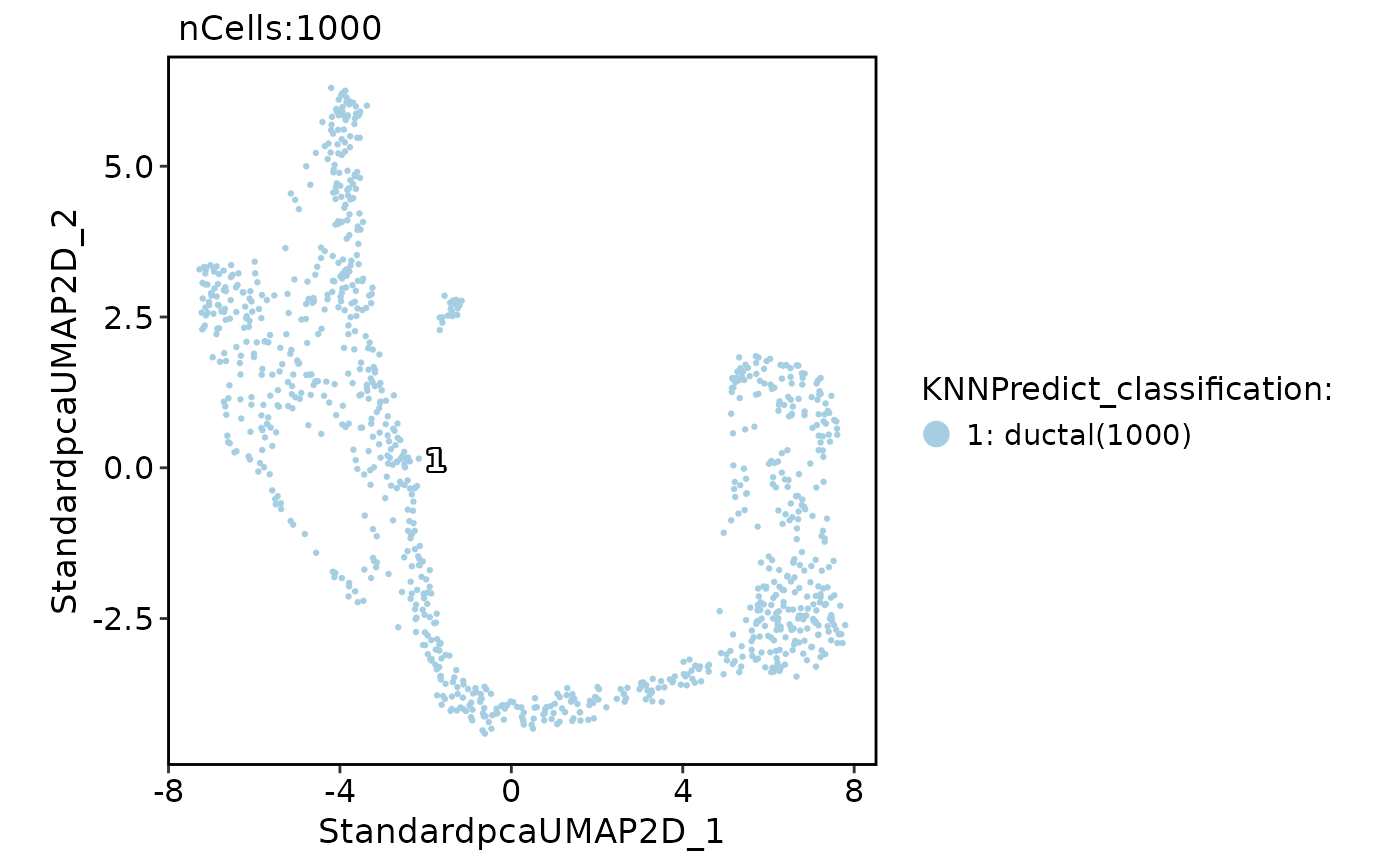
# Annotate with DE gene instead of HVF
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
ref_group = "celltype",
features_type = "DE",
feature_source = "ref",
DEtest_param = list(cores = 2)
)
#> ℹ [2026-07-02 09:44:20] Data type is log-normalized
#> ℹ [2026-07-02 09:44:20] Start differential expression test
#> ℹ [2026-07-02 09:44:20] Find all markers(wilcox) among [1] 13 groups...
#> ℹ [2026-07-02 09:44:20] Using 2 cores
#> ⠙ [2026-07-02 09:44:20] Running for delta [1/13] 8% | ETA: 7s
#> ⠹ [2026-07-02 09:44:20] Running for activated-stellate [6/13] ■■■■ 46% |…
#> ✔ [2026-07-02 09:44:20] Completed 13 tasks in 4.7s
#>
#> ℹ [2026-07-02 09:44:20] Building results
#> ✔ [2026-07-02 09:44:25] Differential expression test completed
#> ℹ [2026-07-02 09:44:25] Use the DE features from AllMarkers_wilcox to calculate distance metric.
#> ℹ [2026-07-02 09:44:25] DE features number of the ref data: [1] 1998
#> ℹ [2026-07-02 09:44:25] Use [1] 1998 features to calculate distance.
#> ℹ [2026-07-02 09:44:25] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:25] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:25] Calculate similarity...
#> ℹ [2026-07-02 09:44:25] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:25] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
 FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
 pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
query_group = "SubCellType",
ref_group = "celltype",
features_type = "DE",
feature_source = "both",
DEtest_param = list(cores = 2)
)
#> ℹ [2026-07-02 09:44:26] Data type is log-normalized
#> ℹ [2026-07-02 09:44:26] Start differential expression test
#> ℹ [2026-07-02 09:44:26] Find all markers(wilcox) among [1] 8 groups...
#> ℹ [2026-07-02 09:44:26] Using 2 cores
#> ⠙ [2026-07-02 09:44:26] Running for Ductal [1/8] ■ 12% | ETA: 3s
#> ⠹ [2026-07-02 09:44:26] Running for Epsilon [7/8] ■■■■■■■■ 88% | ETA: 0s
#> ✔ [2026-07-02 09:44:26] Completed 8 tasks in 2.2s
#>
#> ℹ [2026-07-02 09:44:26] Building results
#> ✔ [2026-07-02 09:44:29] Differential expression test completed
#> ℹ [2026-07-02 09:44:29] Use the DE features from AllMarkers_wilcox to calculate distance metric.
#> ℹ [2026-07-02 09:44:29] DE features number of the query data: [1] 1998
#> ℹ [2026-07-02 09:44:30] Data type is log-normalized
#> ℹ [2026-07-02 09:44:30] Start differential expression test
#> ℹ [2026-07-02 09:44:30] Find all markers(wilcox) among [1] 13 groups...
#> ℹ [2026-07-02 09:44:30] Using 2 cores
#> ⠙ [2026-07-02 09:44:30] Running for alpha [5/13] ■■■ 38% | ETA: 3s
#> ✔ [2026-07-02 09:44:30] Completed 13 tasks in 5.1s
#>
#> ℹ [2026-07-02 09:44:30] Building results
#> ✔ [2026-07-02 09:44:35] Differential expression test completed
#> ℹ [2026-07-02 09:44:35] Use the DE features from AllMarkers_wilcox to calculate distance metric.
#> ℹ [2026-07-02 09:44:35] DE features number of the ref data: [1] 352
#> ℹ [2026-07-02 09:44:35] Use [1] 102 features to calculate distance.
#> ℹ [2026-07-02 09:44:35] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:35] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:35] Calculate similarity...
#> ℹ [2026-07-02 09:44:35] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:35] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
pancreas_sub <- RunKNNPredict(
srt_query = pancreas_sub,
srt_ref = panc8_sub,
query_group = "SubCellType",
ref_group = "celltype",
features_type = "DE",
feature_source = "both",
DEtest_param = list(cores = 2)
)
#> ℹ [2026-07-02 09:44:26] Data type is log-normalized
#> ℹ [2026-07-02 09:44:26] Start differential expression test
#> ℹ [2026-07-02 09:44:26] Find all markers(wilcox) among [1] 8 groups...
#> ℹ [2026-07-02 09:44:26] Using 2 cores
#> ⠙ [2026-07-02 09:44:26] Running for Ductal [1/8] ■ 12% | ETA: 3s
#> ⠹ [2026-07-02 09:44:26] Running for Epsilon [7/8] ■■■■■■■■ 88% | ETA: 0s
#> ✔ [2026-07-02 09:44:26] Completed 8 tasks in 2.2s
#>
#> ℹ [2026-07-02 09:44:26] Building results
#> ✔ [2026-07-02 09:44:29] Differential expression test completed
#> ℹ [2026-07-02 09:44:29] Use the DE features from AllMarkers_wilcox to calculate distance metric.
#> ℹ [2026-07-02 09:44:29] DE features number of the query data: [1] 1998
#> ℹ [2026-07-02 09:44:30] Data type is log-normalized
#> ℹ [2026-07-02 09:44:30] Start differential expression test
#> ℹ [2026-07-02 09:44:30] Find all markers(wilcox) among [1] 13 groups...
#> ℹ [2026-07-02 09:44:30] Using 2 cores
#> ⠙ [2026-07-02 09:44:30] Running for alpha [5/13] ■■■ 38% | ETA: 3s
#> ✔ [2026-07-02 09:44:30] Completed 13 tasks in 5.1s
#>
#> ℹ [2026-07-02 09:44:30] Building results
#> ✔ [2026-07-02 09:44:35] Differential expression test completed
#> ℹ [2026-07-02 09:44:35] Use the DE features from AllMarkers_wilcox to calculate distance metric.
#> ℹ [2026-07-02 09:44:35] DE features number of the ref data: [1] 352
#> ℹ [2026-07-02 09:44:35] Use [1] 102 features to calculate distance.
#> ℹ [2026-07-02 09:44:35] Detected query data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:35] Detected reference data type: "log_normalized_counts"
#> ℹ [2026-07-02 09:44:35] Calculate similarity...
#> ℹ [2026-07-02 09:44:35] Use raw method to find neighbors
#> ℹ [2026-07-02 09:44:35] Predict cell type...
CellDimPlot(
pancreas_sub,
group.by = "KNNPredict_classification",
label = TRUE
)
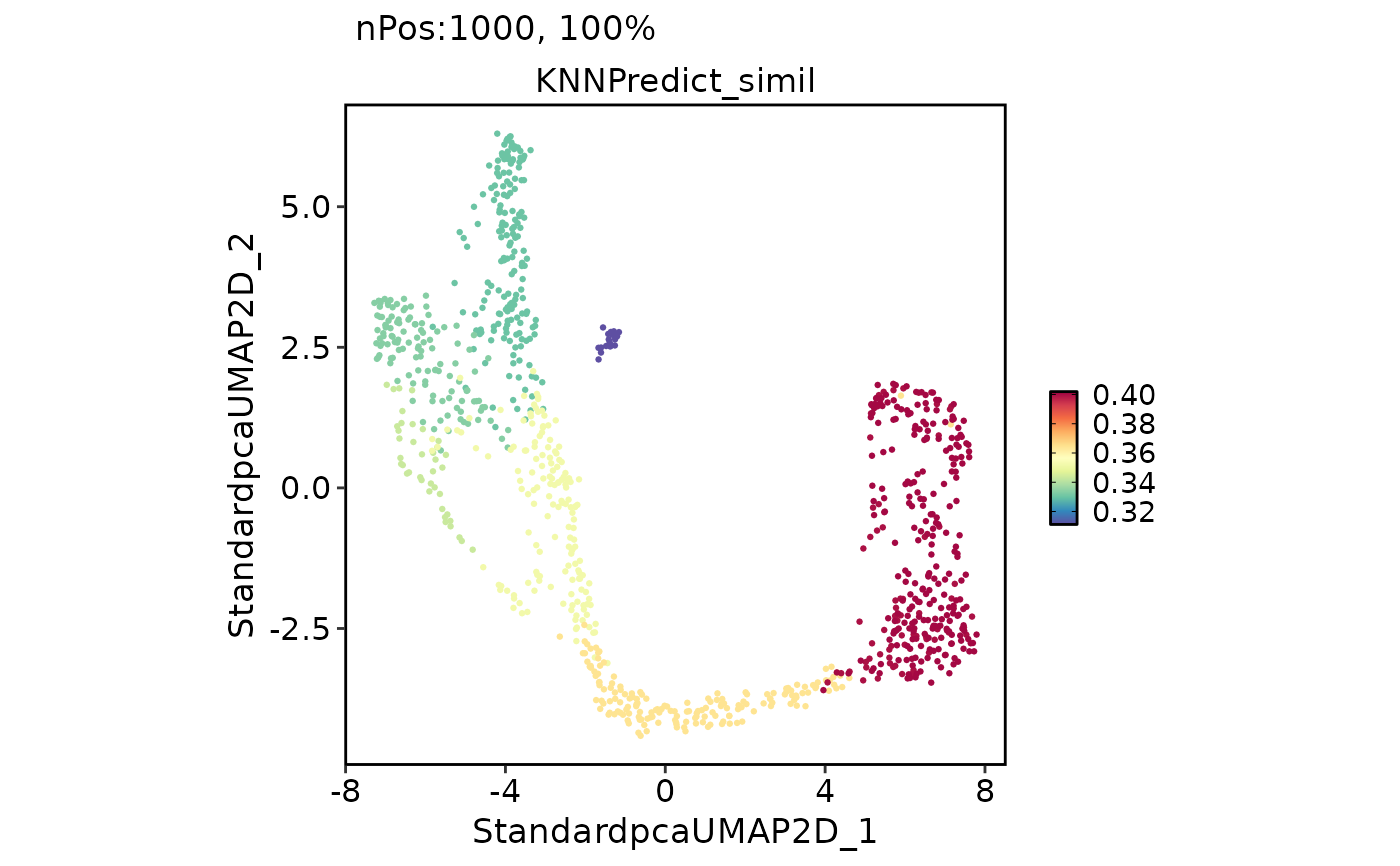
 FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)
FeatureDimPlot(
pancreas_sub,
features = "KNNPredict_simil"
)