Plots for GSVA (Gene Set Variation Analysis)
Usage
GSVAPlot(
srt = NULL,
res = NULL,
group.by = NULL,
sample.by = NULL,
assay_name = "GSVA",
db = NULL,
mode = c("score", "diff"),
plot_type = c("heatmap", "bar", "network", "enrichmap", "wordcloud", "comparison",
"volcano"),
split_by = c("Database", "Groups"),
color_by = "Database",
group_use = NULL,
features = NULL,
topTerm = NULL,
score_cutoff = NULL,
sort.by = c("abs", "score"),
aggregate.fun = c("mean", "median"),
test.use = c("wilcox", "t.test"),
p.adjust.method = "BH",
pvalueCutoff = NULL,
padjustCutoff = NULL,
topWord = 100,
word_type = c("term", "feature"),
word_size = c(2, 8),
network_layout = "fr",
network_labelsize = 5,
network_blendmode = "blend",
network_layoutadjust = TRUE,
network_adjscale = 60,
network_adjiter = 100,
enrichmap_layout = "fr",
enrichmap_cluster = "fast_greedy",
enrichmap_label = c("term", "feature"),
enrichmap_labelsize = 5,
enrlichmap_nlabel = 4,
enrichmap_show_keyword = FALSE,
enrichmap_mark = c("ellipse", "hull"),
enrichmap_expand = c(0.5, 0.5),
words_excluded = NULL,
lineheight = 0.7,
feature_split = NULL,
n_split = NULL,
split_order = NULL,
split_method = c("kmeans", "hclust", "mfuzz"),
decreasing = FALSE,
fuzzification = NULL,
cluster_rows = FALSE,
cluster_columns = FALSE,
cluster_row_slices = FALSE,
show_row_names = FALSE,
show_column_names = FALSE,
row_names_side = "right",
column_names_side = "bottom",
row_names_rot = 0,
column_names_rot = 90,
character_width = 50,
palette = "simspec",
palcolor = NULL,
group_palette = "Chinese",
group_palcolor = NULL,
heatmap_palette = "RdBu",
heatmap_palcolor = NULL,
limits = NULL,
height = NULL,
width = NULL,
units = "inch",
use_raster = NULL,
raster_device = "png",
raster_by_magick = FALSE,
ht_params = list(),
aspect.ratio = 1,
legend.position = "right",
legend.direction = "vertical",
theme_use = "theme_scop",
theme_args = list(),
combine = TRUE,
return_data = FALSE,
nrow = NULL,
ncol = NULL,
byrow = TRUE,
border = TRUE,
nlabel = 0,
seed = 11,
verbose = TRUE
)Arguments
- srt
A Seurat object containing the results of RunGSVA. If specified, GSVA results will be extracted from the
Seuratobject automatically. If not specified, theresargument must be provided.- res
GSVA results generated by RunGSVA function. If provided, 'srt' and 'group.by' are ignored.
- group.by
A character vector specifying the grouping variable used in RunGSVA.
- sample.by
Metadata column identifying biological samples for sample-level aggregation. Required when
mode = "diff".- assay_name
The name of the assay or tools slot containing GSVA results. Default is
"GSVA".- db
The database name used in RunGSVA. Only used for compatibility with EnrichmentPlot. Default is
NULL(will be inferred from GSVA results or set to "GSVA").- mode
Plot mode.
"score"keeps the original GSVA score plotting behavior;"diff"performs a two-group differential pathway activity test on sample-aggregated GSVA scores.- plot_type
The type of plot to generate. Options are:
"heatmap","bar","network","enrichmap","wordcloud","comparison", and"volcano". When omitted, the default is"heatmap"formode = "score"and"volcano"formode = "diff".- split_by
The splitting variable(s) for the plot. Can be
"Database","Groups", or both. Default is"Database".- color_by
The variable used for coloring. Default is
"Database".- group_use
The group(s) to be used for GSVA plot. Default is
NULL(all groups).- features
A character vector of features to use. Default is
NULL.- topTerm
A number of top terms to include. Default is
5.- score_cutoff
The score cutoff for the GSVA plot. Default is
NULL(no cutoff).- sort.by
Ranking metric used when
return_data = TRUEinmode = "score"."abs"uses absolute GSVA score and"score"uses signed GSVA score.- aggregate.fun
Function used to aggregate cells within each
sample.byandgroup.bycombination inmode = "diff". Supports"mean"and"median".- test.use
Statistical test for
mode = "diff". Supports"wilcox"and"t.test".- p.adjust.method
Multiple-testing correction method passed to
stats::p.adjust()inmode = "diff".- pvalueCutoff
A numeric vector specifying the p-value cutoff(s) for significance. Default is
NULL.- padjustCutoff
The adjusted p-value cutoff for significance. Default is
0.05.- topWord
A number of top words to include. Default is
20.- word_type
The type of words to display in wordcloud. Options are
"term"and"feature". Default is"term".- word_size
The size range for words in wordcloud. Default is
c(2, 8).- network_layout
The layout algorithm to use for network plot. Options are
"fr","kk","random","circle","tree","grid", or other algorithm fromigraphpackage. Default is"fr".- network_labelsize
The label size for network plot. Default is
5.- network_blendmode
The blend mode for network plot. Default is
"blend".- network_layoutadjust
Whether to adjust the layout of the network plot to avoid overlapping words. Default is
TRUE.- network_adjscale
The scale for adjusting network plot layout. Default is
60.- network_adjiter
The number of iterations for adjusting network plot layout. Default is
100.- enrichmap_layout
The layout algorithm to use for enrichmap plot. Options are
"fr","kk","random","circle","tree","grid", or other algorithm fromigraphpackage. Default is"fr".- enrichmap_cluster
The clustering algorithm to use for enrichmap plot. Options are
"walktrap","fast_greedy", or other algorithm fromigraphpackage. Default is"fast_greedy".- enrichmap_label
The label type for enrichmap plot. Options are
"term"and"feature". Default is"term".- enrichmap_labelsize
The label size for enrichmap plot. Default is
5.- enrlichmap_nlabel
The number of labels to display for each cluster in enrichmap plot. Default is
4.- enrichmap_show_keyword
Whether to show the keyword of terms or features in enrichmap plot. Default is
FALSE.- enrichmap_mark
The mark shape for enrichmap plot. Options are
"ellipse"and"hull". Default is"ellipse".- enrichmap_expand
The expansion factor for enrichmap plot. Default is
c(0.5, 0.5).- words_excluded
A character vector specifying the words to exclude. Default is
NULL.- lineheight
The line height for y-axis labels. Default is
0.7.- feature_split
A factor specifying how to split the features. Default is
NULL.- n_split
A number of feature splits (feature clusters) to create. Default is
NULL.- split_order
A numeric vector specifying the order of splits. Default is
NULL.- split_method
A character vector specifying the method for splitting features. Options are
"kmeans","hclust", or"mfuzz". Default is"kmeans".- decreasing
Whether to sort feature splits in decreasing order. Default is
FALSE.- fuzzification
The fuzzification coefficient. Default is
NULL.- cluster_rows
Whether to cluster rows in the heatmap. Default is
FALSE.- cluster_columns
Whether to cluster columns in the heatmap. Default is
FALSE.- cluster_row_slices
Whether to cluster row slices in the heatmap. Default is
FALSE.- show_row_names
Whether to show row names in the heatmap. Default is
FALSE.- show_column_names
Whether to show column names in the heatmap. Default is
FALSE.- row_names_side
A character vector specifying the side to place row names.
- column_names_side
A character vector specifying the side to place column names.
- row_names_rot
The rotation angle for row names. Default is
0.- column_names_rot
The rotation angle for column names. Default is
90.- character_width
The maximum width of character of descriptions. Default is
50.- palette
Color palette name. Available palettes can be found in thisplot::show_palettes. Default is
"Chinese".- palcolor
Custom colors used to create a color palette. Default is
NULL.- group_palette
A character vector specifying the palette to use for groups. Default is
"Chinese".- group_palcolor
A character vector specifying the group color to use. Default is
NULL.- heatmap_palette
A character vector specifying the palette to use for the heatmap. Default is
"RdBu".- heatmap_palcolor
A character vector specifying the heatmap color to use. Default is
NULL.- limits
A two-length numeric vector specifying the limits for the color scale. Default is
NULL.- height
The height of the heatmap in the specified units. If not provided, the height will be automatically determined based on the number of rows in the heatmap and the default unit.
- width
The width of the heatmap in the specified units. If not provided, the width will be automatically determined based on the number of columns in the heatmap and the default unit.
- units
The units to use for the width and height of the heatmap. Default is
"inch", Options are"mm","cm", or"inch".- use_raster
Whether to use a raster device for plotting. Default is
NULL.- raster_device
A character vector specifying the raster device to use. Default is
"png".- raster_by_magick
Whether to use the 'magick' package for raster. Default is
FALSE.- ht_params
Additional parameters to customize the appearance of the heatmap. This should be a list with named elements, where the names correspond to parameter names in the ComplexHeatmap::Heatmap function. Any conflicting parameters will override the defaults set by this function. Default is
list().- aspect.ratio
Aspect ratio of the panel. Default is
1.- legend.position
The position of legends, one of
"none","left","right","bottom","top". Default is"right".- legend.direction
The direction of the legend in the plot. Can be one of
"vertical"or"horizontal".- theme_use
Theme used. Can be a character string or a theme function. Default is
"theme_scop".- theme_args
Other arguments passed to the
theme_use. Default islist().- combine
Combine plots into a single
patchworkobject. IfFALSE, return a list of ggplot objects.- return_data
Whether to return the ranking/statistics table instead of a plot.
- nrow
Number of rows in the combined plot. Default is
NULL, which means determined automatically based on the number of plots.- ncol
Number of columns in the combined plot. Default is
NULL, which means determined automatically based on the number of plots.- byrow
Whether to arrange the plots by row in the combined plot. Default is
TRUE.- border
Whether to add borders to the heatmap body and annotations. Kept for backward compatibility. The more specific
heatmap_border,cell_annotation_border, andfeature_annotation_borderarguments inherit from this value when left asNULL.- nlabel
A number of labels to include. Default is
20.- seed
Random seed for reproducibility. Default is
11.- verbose
Whether to print the message. Default is
TRUE.
Details
GSVA itself returns pathway activity/enrichment scores, not statistical
p-values. In mode = "score", non-heatmap plot types fill pvalue and
p.adjust internally only to satisfy the shared EnrichmentPlot() interface;
these score-derived placeholders should not be interpreted as pathway
significance. Use mode = "diff" for real group-level statistical tests on
GSVA scores.
Examples
data(pancreas_sub)
pancreas_sub <- pancreas_sub[, 1:80]
pancreas_sub <- Seurat::NormalizeData(pancreas_sub, verbose = FALSE)
features_all <- rownames(pancreas_sub)
pancreas_sub <- RunGSVA(
pancreas_sub,
features = list(
A = features_all[1:5],
B = features_all[6:10]
),
method = "zscore",
minGSSize = 2,
min.sz = 2
)
#> ℹ [2026-07-02 09:06:06] Start GSVA analysis
#> ℹ [2026-07-02 09:06:06] Single-cell GSVA mode: using expression matrix directly ...
#> ℹ [2026-07-02 09:06:06] Expression matrix: 12238 genes x 80 cells
#> ℹ [2026-07-02 09:06:06] Processing database: "custom" ...
#> ℹ [2026-07-02 09:06:06] Initial overlap: 6 genes out of 12238 expression genes and 10 genes in gene sets
#> ℹ [2026-07-02 09:06:06] Running GSVA for 2 gene sets ...
#> Warning: Feature names cannot have underscores ('_'), replacing with dashes ('-')
#> Warning: Layer counts isn't present in the assay object; returning NULL
#> ℹ [2026-07-02 09:06:06] GSVA results stored in assay "GSVA", meta.data, and tools slot "GSVA_cell_zscore"
#> ✔ [2026-07-02 09:06:06] GSVA analysis done
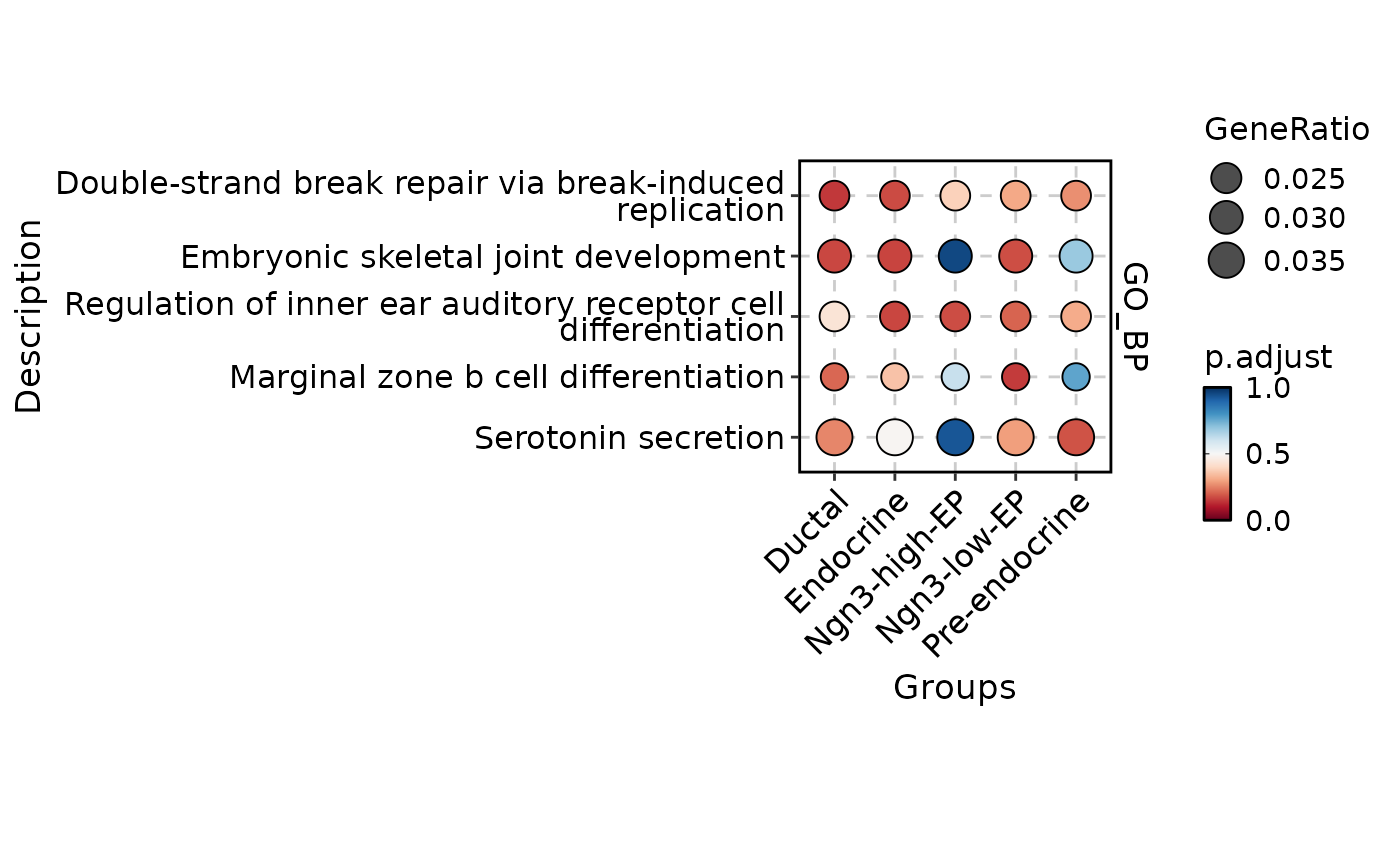
ht <- GSVAPlot(
pancreas_sub,
plot_type = "heatmap",
group.by = "CellType",
topTerm = 2,
width = 1,
height = 2
)
#> Warning: Data is of class matrix. Coercing to dgCMatrix.
ht$plot
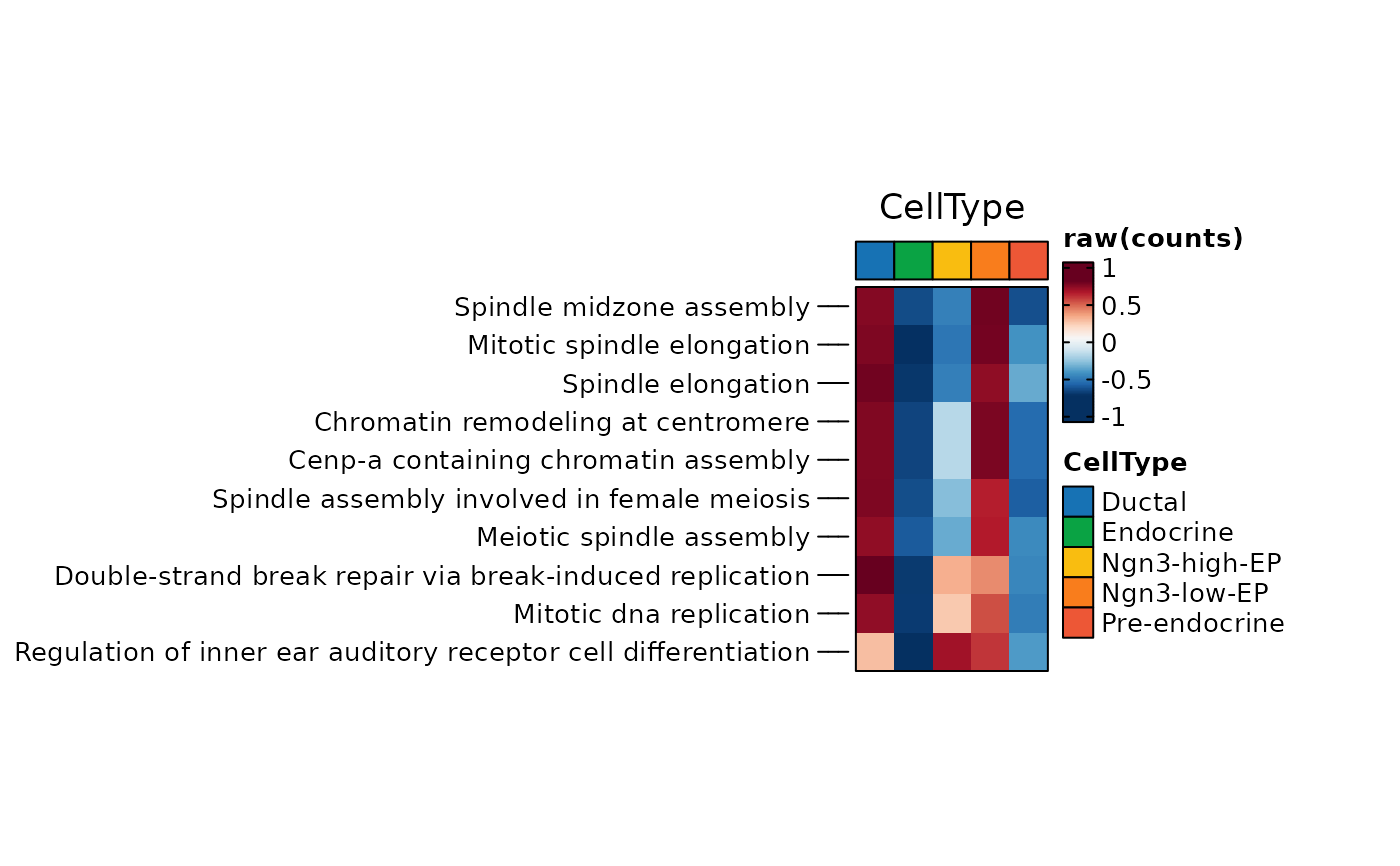 GSVAPlot(
srt = pancreas_sub,
group.by = "CellType",
plot_type = "comparison",
topTerm = 1
)
GSVAPlot(
srt = pancreas_sub,
group.by = "CellType",
plot_type = "comparison",
topTerm = 1
)
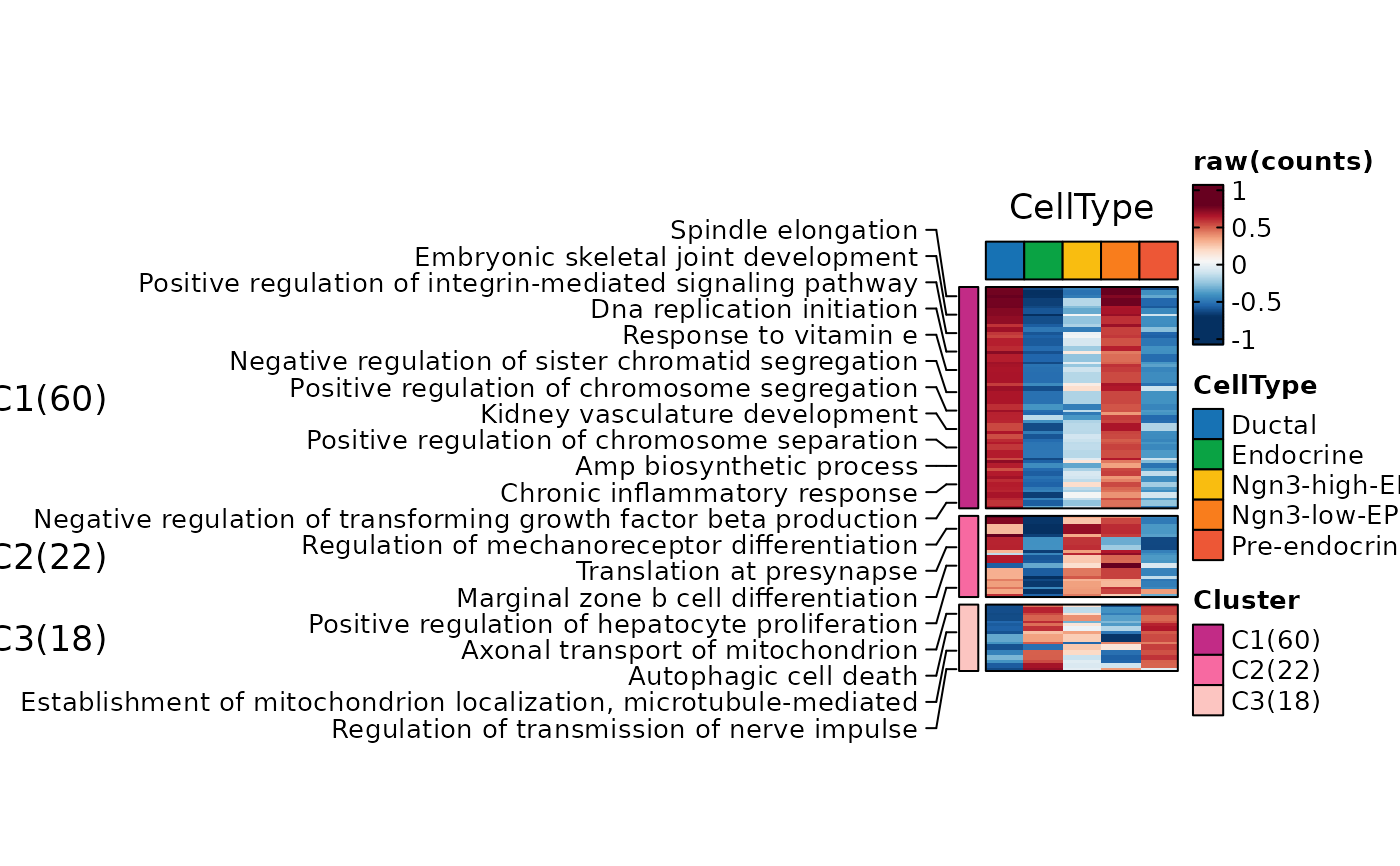 GSVAPlot(
srt = pancreas_sub,
group.by = "CellType",
plot_type = "bar",
topTerm = 2
)
GSVAPlot(
srt = pancreas_sub,
group.by = "CellType",
plot_type = "bar",
topTerm = 2
)