Differential Expression Test Plot
Usage
DEtestPlot(
srt,
group.by = NULL,
test.use = "wilcox",
res = NULL,
plot_type = c("volcano", "manhattan", "ring"),
group_use = NULL,
DE_threshold = "avg_log2FC > 0 & p_val_adj < 0.05",
x_metric = NULL,
y_metric = c("p_val_adj", "p_val"),
x_order = c("gene", "index"),
palette = "RdBu",
palcolor = NULL,
group_palette = "Chinese",
group_palcolor = NULL,
pt.size = 1,
pt.alpha = 1,
cols.background = "grey80",
cols.highlight = "black",
sizes.highlight = 1,
alpha.highlight = 1,
stroke.highlight = 0.5,
nlabel = 5,
features_label = NULL,
only.pos = FALSE,
label.by = c("p_val_adj", "p_val", "diff_pct", "avg_log2FC"),
label.fg = "black",
label.bg = "white",
label.bg.r = 0.1,
label.size = 4,
aspect.ratio = NULL,
xlab = NULL,
ylab = NULL,
theme_use = "theme_scop",
theme_args = list(),
combine = TRUE,
nrow = NULL,
ncol = NULL,
byrow = TRUE,
manhattan.bg = "white",
group_track_width = NULL,
group_track_height = NULL,
jitter_width = 0.5,
jitter_height = 0,
tile_height = 0.3,
tile_gap = 0.1,
ring_segments = TRUE,
seed = 11,
threshold_method = c("rectangular", "hyperbolic"),
hyperbola_c = 6,
annotate_enrichment = FALSE,
enrich_from = c("Enrichment", "GSEA", "GSVA"),
enrich_db = NULL,
enrich_terms = NULL,
enrich_top_terms = 3,
enrich_padj_cutoff = 0.05,
enrich_gsva_score_cutoff = NULL,
gsva_method = NULL,
enrich_nlabel = 15
)Arguments
- srt
A
Seuratobject orSummarizedExperimentobject containing the results of differential expression analysis.- group.by
Name of one or more meta.data columns to group (color) cells by.
- test.use
A character string specifying the type of statistical test to use. Default is
"wilcox".- res
A
data.frameordata.tablewith differential expression results. Whenresis provided,srtwill be ignored. The data.frame must contain columns:gene,group1(factor or character),avg_log2FC,p_val_adj, and optionallypct.1andpct.2for calculatingdiff_pct.- plot_type
Type of plot to create. Options:
"volcano","manhattan", or"ring". Default is"volcano".- group_use
Groups to plot. Default is
NULL(all groups).- DE_threshold
A character string specifying the threshold for differential expression (used to highlight significant genes in all plot types). Default is
"p_val < 0.05"for sample-level methods ("edgeR"and"limma"). For cell-level volcano plots, it is"abs(avg_log2FC) > 0 & p_val_adj < 0.05"whenonly.pos = FALSE, and"avg_log2FC > 0 & p_val_adj < 0.05"otherwise.- x_metric
A character string specifying the metric to use for the x-axis (only for volcano plot). Default is
NULL, which uses"avg_log2FC"for sample-level methods ("edgeR"and"limma") and"diff_pct"otherwise.- y_metric
A character string specifying the metric to use for the y-axis. Options:
"p_val"or"p_val_adj". Default is"p_val"for sample-level methods ("edgeR"and"limma") and"p_val_adj"otherwise.- x_order
A character string specifying how to order genes on x-axis (only for Manhattan plot, not used currently). Options:
"gene"(alphabetical by gene name) or"index"(by data order). Default is"gene".- palette
Color palette name. Available palettes can be found in thisplot::show_palettes. Default is
"RdBu".- palcolor
Custom colors used to create a color palette. Default is
NULL.- group_palette
Palette for cell types (groups) in Manhattan plot. Default is
"Chinese".- group_palcolor
Custom colors for cell types (groups) in Manhattan plot. Default is
NULL.- pt.size
The size of the points. Default is
1.- pt.alpha
The transparency of the data points. Default is
1.- cols.background
A character string specifying the color for non-DE background points in volcano plots. Default is
"grey80".- cols.highlight
A character string specifying the color for highlighted points. Default is
"black".- sizes.highlight
The size of the highlighted points. Default is
1.- alpha.highlight
The transparency of the highlighted points. Default is
1.- stroke.highlight
The stroke width for the highlighted points. Default is
0.5.- nlabel
An integer value specifying the number of labeled points per group. Default is
5.- features_label
A character vector specifying the feature labels to plot. Default is
NULL.- only.pos
Whether to show only positive log2 fold-change results in differential expression visualizations. Default is
FALSE.- label.by
Metric used to select automatic labels when
features_label = NULL. Options are"p_val_adj","p_val","diff_pct", and"avg_log2FC". Smaller p-values are ranked first;diff_pctandavg_log2FCuse the strongest positive and negative effects within each group. Default is"p_val_adj".- label.fg
A character string specifying the color for the labels' foreground. Default is
"black".- label.bg
A character string specifying the color for the labels' background. Default is
"white".- label.bg.r
The radius of the rounding of the labels' background. Default is
0.1.- label.size
The size of the labels. Default is
4.- aspect.ratio
Aspect ratio of the panel. Default is
NULL.- xlab
A character string specifying the x-axis label.
- ylab
A character string specifying the y-axis label.
- theme_use
Theme to use for the plot. Default is
"theme_scop".- theme_args
A list of additional arguments to pass to the theme function. Default is
list().- combine
Whether to combine multiple plots into one. Default is
TRUE.- nrow
Number of rows for combined plots. Default is
NULL.- ncol
Number of columns for combined plots. Default is
NULL.- byrow
Whether to fill plots by row. Default is
TRUE.- manhattan.bg
Background color for Manhattan plot. Default is
"white".- group_track_width
Width of the centered cell-type track in Manhattan plot. Default is
NULL, which uses the current automatic width.- group_track_height
Height of the centered cell-type track in Manhattan plot. Default is
NULL, which uses the current automatic height.- jitter_width
Horizontal jitter range for points in Manhattan plot. Default is
0.5.- jitter_height
Vertical jitter range for points in Manhattan plot. Default is
0.- tile_height
Height of the cell-type track in ring plot. Default is
0.3.- tile_gap
Gap between the track and nudged points in ring plot. Default is
0.1.- ring_segments
Whether to draw segment lines between cell types in ring plot. Default is
TRUE.- seed
Random seed for jitter in Manhattan and ring plots. Default is
11.- threshold_method
Volcano significance threshold method. Options are
"rectangular"(legacy DE_threshold) or"hyperbolic"(|log2FC * -log10(padj)| > c). Default is"rectangular".- hyperbola_c
Numeric cutoff
cfor hyperbolic volcano threshold. Default is6.- annotate_enrichment
Whether to annotate enrichment-hit genes on volcano plots. Enrichment results are read from existing results in
srt@toolsonly. Default isFALSE.- enrich_from
Character vector specifying enrichment result source(s) to annotate. Options are
"Enrichment","GSEA","GSVA". Default isc("Enrichment", "GSEA", "GSVA").- enrich_db
Optional database filter for enrichment annotation, e.g.
"GO_BP"or"KEGG". Default isNULL.- enrich_terms
Optional whitelist of enrichment term IDs or names for annotation. Default is
NULL.- enrich_top_terms
Number of top enriched terms selected per source/group/database. Default is
3.- enrich_padj_cutoff
Adjusted p-value cutoff for
"Enrichment"and"GSEA"annotation. Default is0.05.- enrich_gsva_score_cutoff
Optional absolute GSVA score cutoff for
"GSVA"annotation. Default isNULL.- gsva_method
Optional GSVA method filter (e.g.
"gsva"or"ssgsea") when multiple GSVA tool slots exist. Default isNULL.- enrich_nlabel
Maximum number of enrichment-derived labels added per group. Labels from
features_labelare always retained. Default is15.
Examples
data(pancreas_sub)
pancreas_sub <- standard_scop(pancreas_sub)
#> ℹ [2026-07-20 17:19:33] Start standard processing workflow...
#> ℹ [2026-07-20 17:19:33] Checking a list of <Seurat>...
#> ! [2026-07-20 17:19:33] Data 1/1 of the `srt_list` is "unknown"
#> ℹ [2026-07-20 17:19:33] Perform `NormalizeData()` with `normalization.method = 'LogNormalize'` on 1/1 of `srt_list`...
#> ℹ [2026-07-20 17:19:33] Perform `FindVariableFeatures()` on 1/1 of `srt_list`...
#> ℹ [2026-07-20 17:19:33] Use the separate HVF from `srt_list`
#> ℹ [2026-07-20 17:19:34] Number of available HVF: 2000
#> ℹ [2026-07-20 17:19:34] Finished check
#> ℹ [2026-07-20 17:19:34] Perform `ScaleData()`
#> ℹ [2026-07-20 17:19:34] Perform pca linear dimension reduction
#> ℹ [2026-07-20 17:19:35] Use stored estimated dimensions 1:23 for Standardpca
#> ℹ [2026-07-20 17:19:35] Perform `Seurat::FindClusters()` with `cluster_algorithm = 'louvain'` and `cluster_resolution = 0.6`
#> ℹ [2026-07-20 17:19:35] Reorder clusters...
#> ℹ [2026-07-20 17:19:36] Skip `log1p()` because `layer = data` is not "counts"
#> ℹ [2026-07-20 17:19:36] Perform umap nonlinear dimension reduction
#> ✔ [2026-07-20 17:19:41] Standard processing workflow completed
pancreas_sub <- RunDEtest(
pancreas_sub,
group.by = "CellType",
only.pos = FALSE
)
#> ℹ [2026-07-20 17:19:41] Data type is log-normalized
#> ℹ [2026-07-20 17:19:41] Start differential expression test
#> ℹ [2026-07-20 17:19:41] Find all markers(wilcox) among [1] 5 groups...
#> ℹ [2026-07-20 17:19:41] Using 1 core
#> ⠙ [2026-07-20 17:19:41] Running for Ductal [1/5] ■■ 20% | ETA: 1s
#> ✔ [2026-07-20 17:19:41] Completed 5 tasks in 1.2s
#>
#> ℹ [2026-07-20 17:19:41] Building results
#> ✔ [2026-07-20 17:19:43] Differential expression test completed
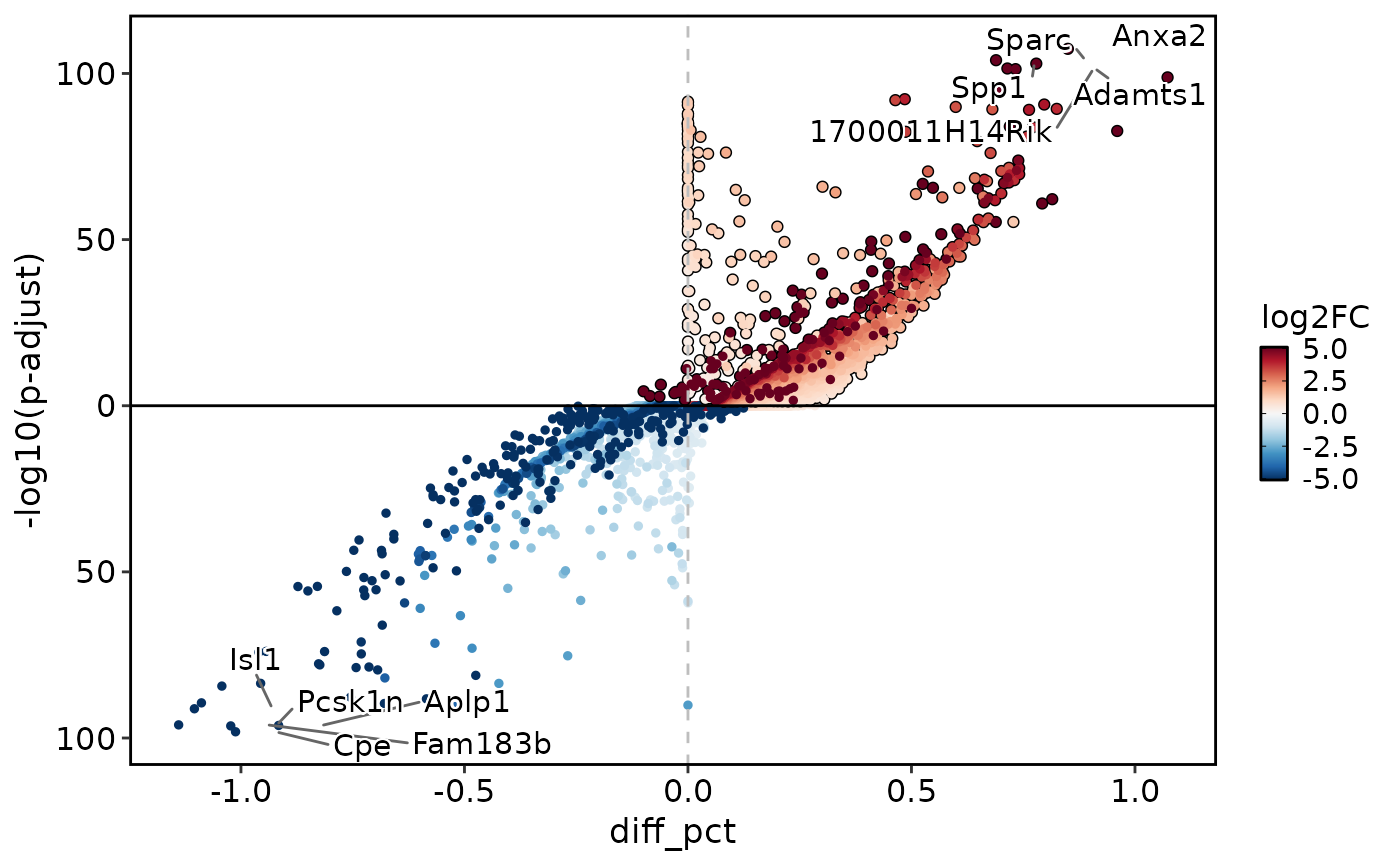
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
ncol = 2
)
 DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
group_use = c("Ductal", "Endocrine"),
ncol = 2
)
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
group_use = c("Ductal", "Endocrine"),
ncol = 2
)
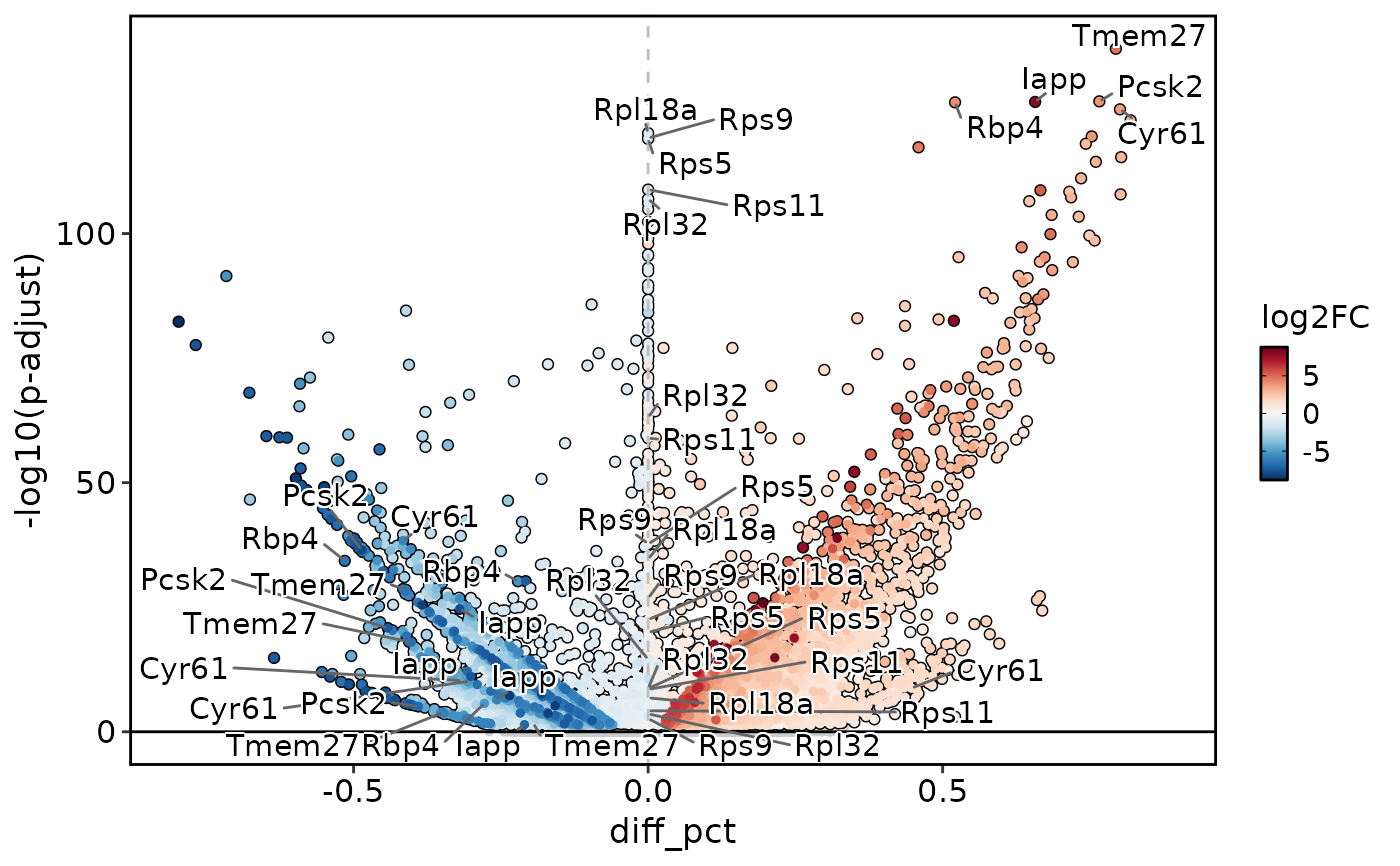
 DEtestPlot(
pancreas_sub,
group.by = "CellType",
test.use = "wilcox",
plot_type = "volcano",
x_metric = "avg_log2FC",
y_metric = "p_val_adj",
group_use = c("Ductal", "Endocrine"),
DE_threshold = "abs(avg_log2FC) > 0.25 & p_val_adj < 0.05"
)
DEtestPlot(
pancreas_sub,
group.by = "CellType",
test.use = "wilcox",
plot_type = "volcano",
x_metric = "avg_log2FC",
y_metric = "p_val_adj",
group_use = c("Ductal", "Endocrine"),
DE_threshold = "abs(avg_log2FC) > 0.25 & p_val_adj < 0.05"
)
 DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
threshold_method = "hyperbolic",
hyperbola_c = 6,
ncol = 2
)
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
threshold_method = "hyperbolic",
hyperbola_c = 6,
ncol = 2
)
 pancreas_sub <- RunEnrichment(
pancreas_sub,
group.by = "CellType",
db = "GO_BP",
species = "Mus_musculus"
)
#> ℹ [2026-07-20 17:19:50] Start Enrichment analysis
#> ℹ [2026-07-20 17:19:50] Species: "Mus_musculus"
#>
#>
#> ℹ [2026-07-20 17:24:58] Preparing database: GO_BP
#> ℹ [2026-07-20 17:25:29] Convert ID types for the GO_BP database
#> ℹ [2026-07-20 17:25:29] Converted ID types using local annotation package org.Mm.eg.db
#> ℹ [2026-07-20 17:25:30] Permform enrichment...
#> ℹ [2026-07-20 17:25:32] Using 1 core
#> ⠙ [2026-07-20 17:25:32] Running for 1 [1/5] ■■ 20% | ETA: 8s
#> ⠹ [2026-07-20 17:25:32] Running for 2 [2/5] ■■■■ 40% | ETA: 6s
#> ⠸ [2026-07-20 17:25:32] Running for 4 [4/5] ■■■■■■■■ 80% | ETA: 2s
#> ✔ [2026-07-20 17:25:32] Completed 5 tasks in 9.7s
#>
#> ℹ [2026-07-20 17:25:32] Building results
#> ✔ [2026-07-20 17:25:41] Enrichment analysis done
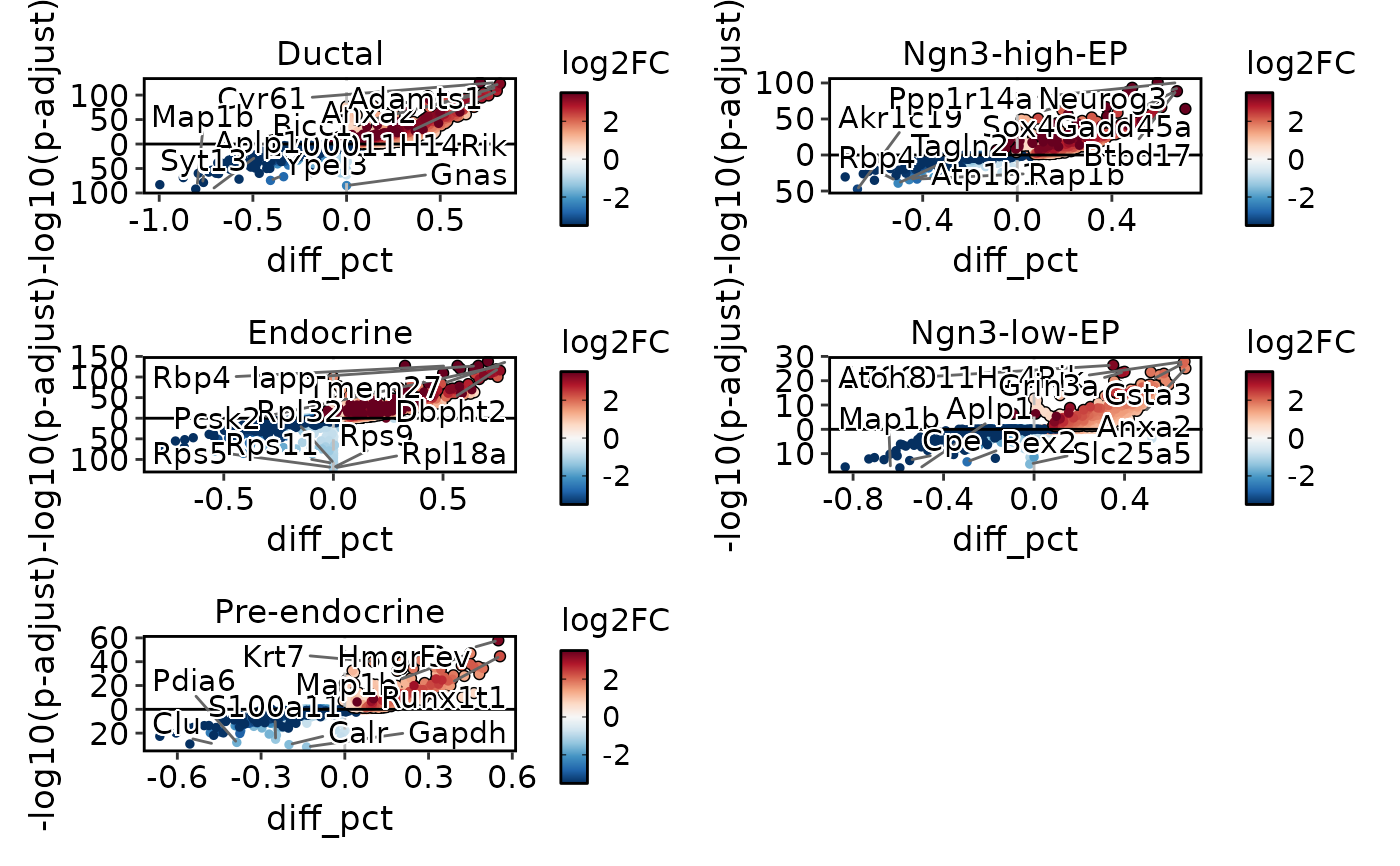
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
threshold_method = "hyperbolic",
hyperbola_c = 6,
annotate_enrichment = TRUE,
enrich_from = "Enrichment",
enrich_db = "GO_BP",
enrich_top_terms = 3,
enrich_nlabel = 15,
ncol = 2
)
pancreas_sub <- RunEnrichment(
pancreas_sub,
group.by = "CellType",
db = "GO_BP",
species = "Mus_musculus"
)
#> ℹ [2026-07-20 17:19:50] Start Enrichment analysis
#> ℹ [2026-07-20 17:19:50] Species: "Mus_musculus"
#>
#>
#> ℹ [2026-07-20 17:24:58] Preparing database: GO_BP
#> ℹ [2026-07-20 17:25:29] Convert ID types for the GO_BP database
#> ℹ [2026-07-20 17:25:29] Converted ID types using local annotation package org.Mm.eg.db
#> ℹ [2026-07-20 17:25:30] Permform enrichment...
#> ℹ [2026-07-20 17:25:32] Using 1 core
#> ⠙ [2026-07-20 17:25:32] Running for 1 [1/5] ■■ 20% | ETA: 8s
#> ⠹ [2026-07-20 17:25:32] Running for 2 [2/5] ■■■■ 40% | ETA: 6s
#> ⠸ [2026-07-20 17:25:32] Running for 4 [4/5] ■■■■■■■■ 80% | ETA: 2s
#> ✔ [2026-07-20 17:25:32] Completed 5 tasks in 9.7s
#>
#> ℹ [2026-07-20 17:25:32] Building results
#> ✔ [2026-07-20 17:25:41] Enrichment analysis done
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "volcano",
threshold_method = "hyperbolic",
hyperbola_c = 6,
annotate_enrichment = TRUE,
enrich_from = "Enrichment",
enrich_db = "GO_BP",
enrich_top_terms = 3,
enrich_nlabel = 15,
ncol = 2
)
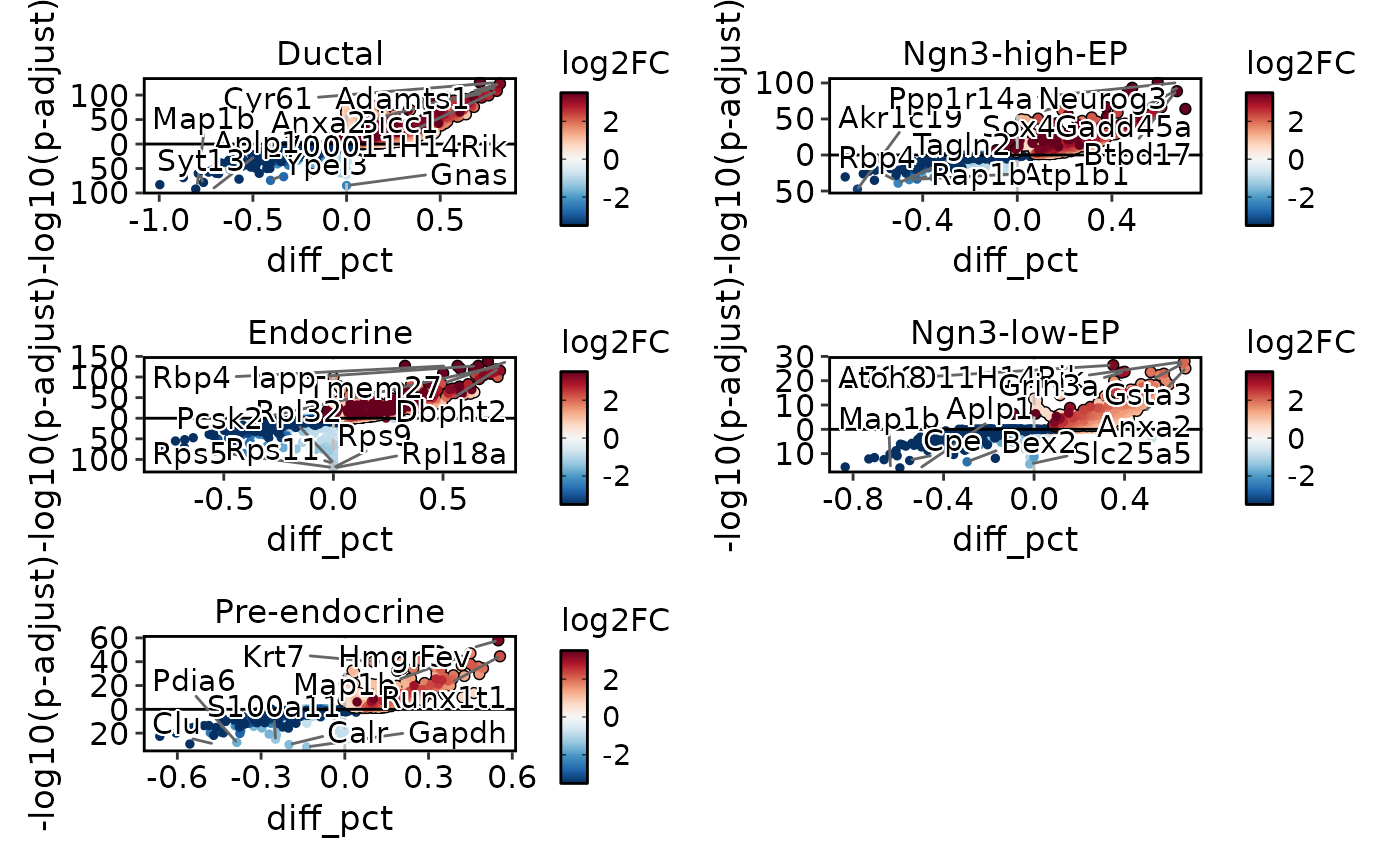
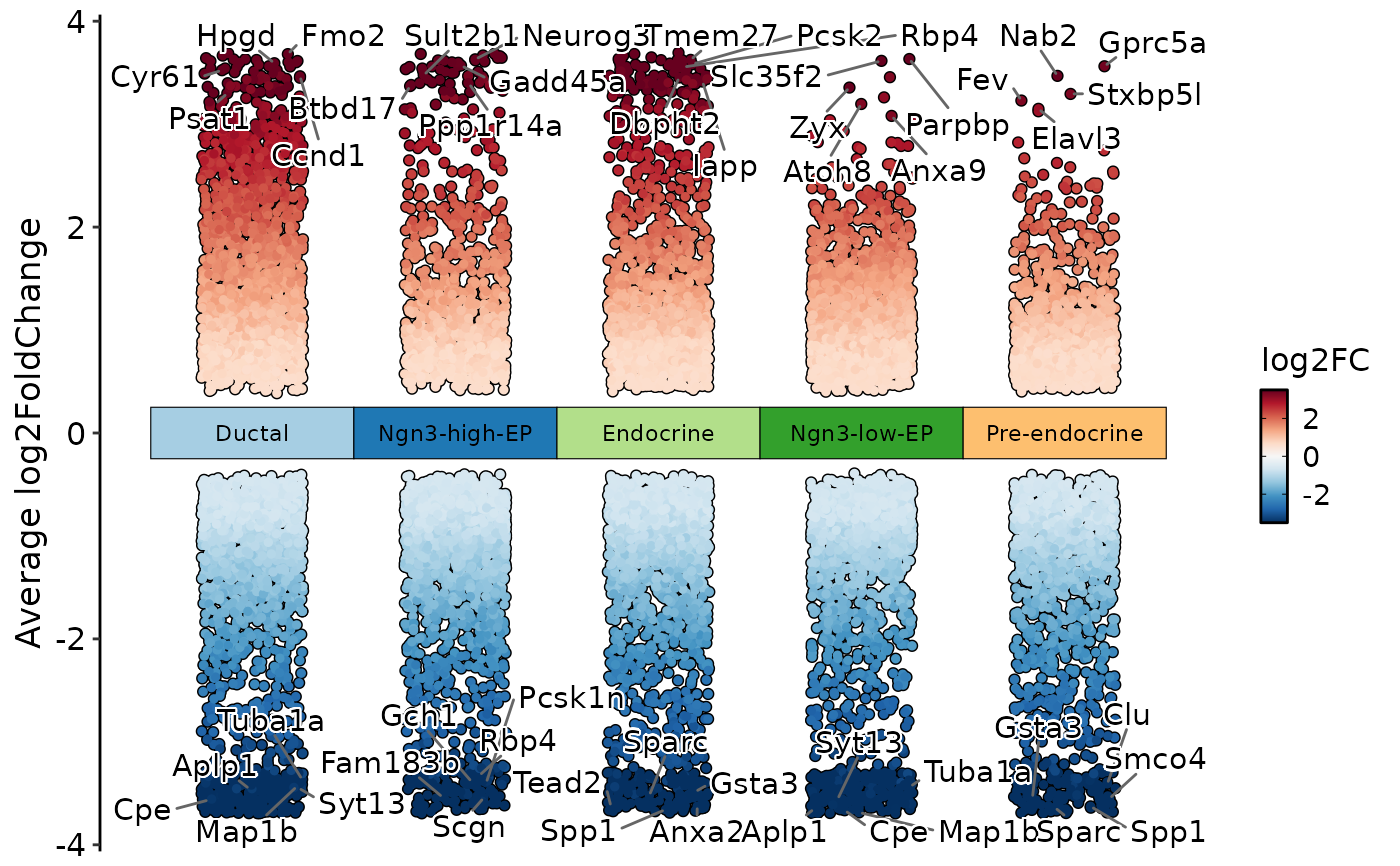
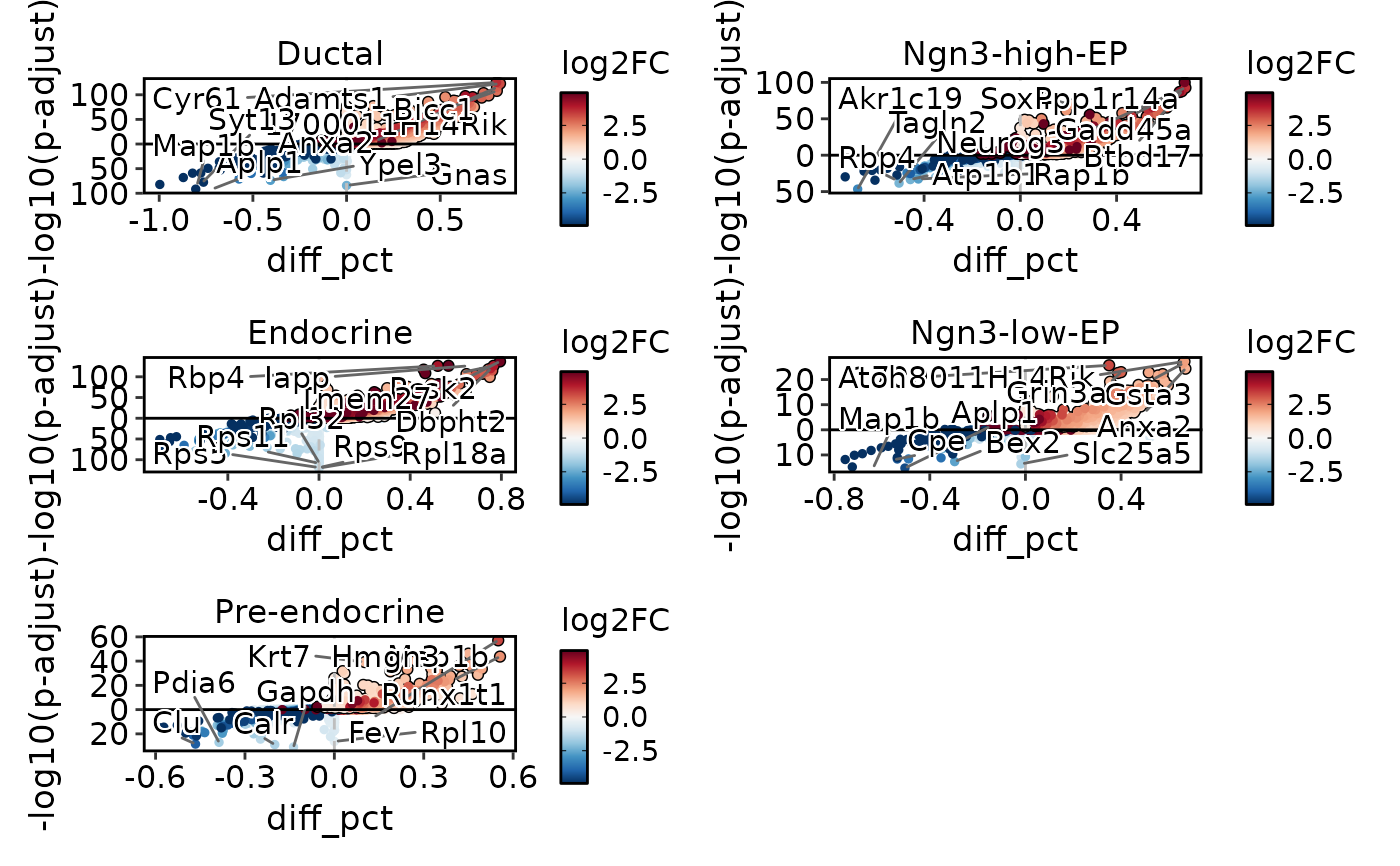
 DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "manhattan"
)
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "manhattan"
)
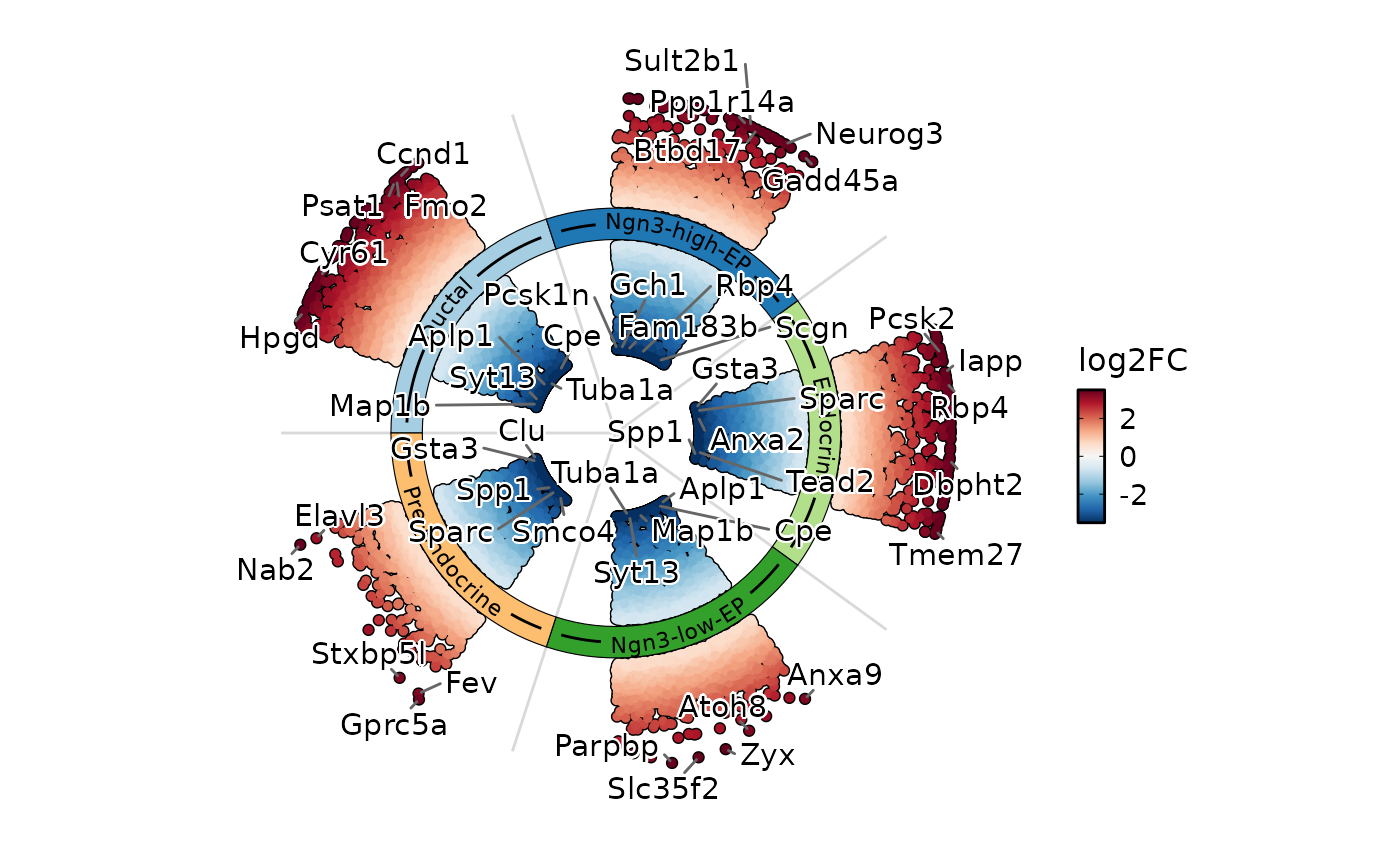
 DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "ring"
)
DEtestPlot(
pancreas_sub,
group.by = "CellType",
plot_type = "ring"
)
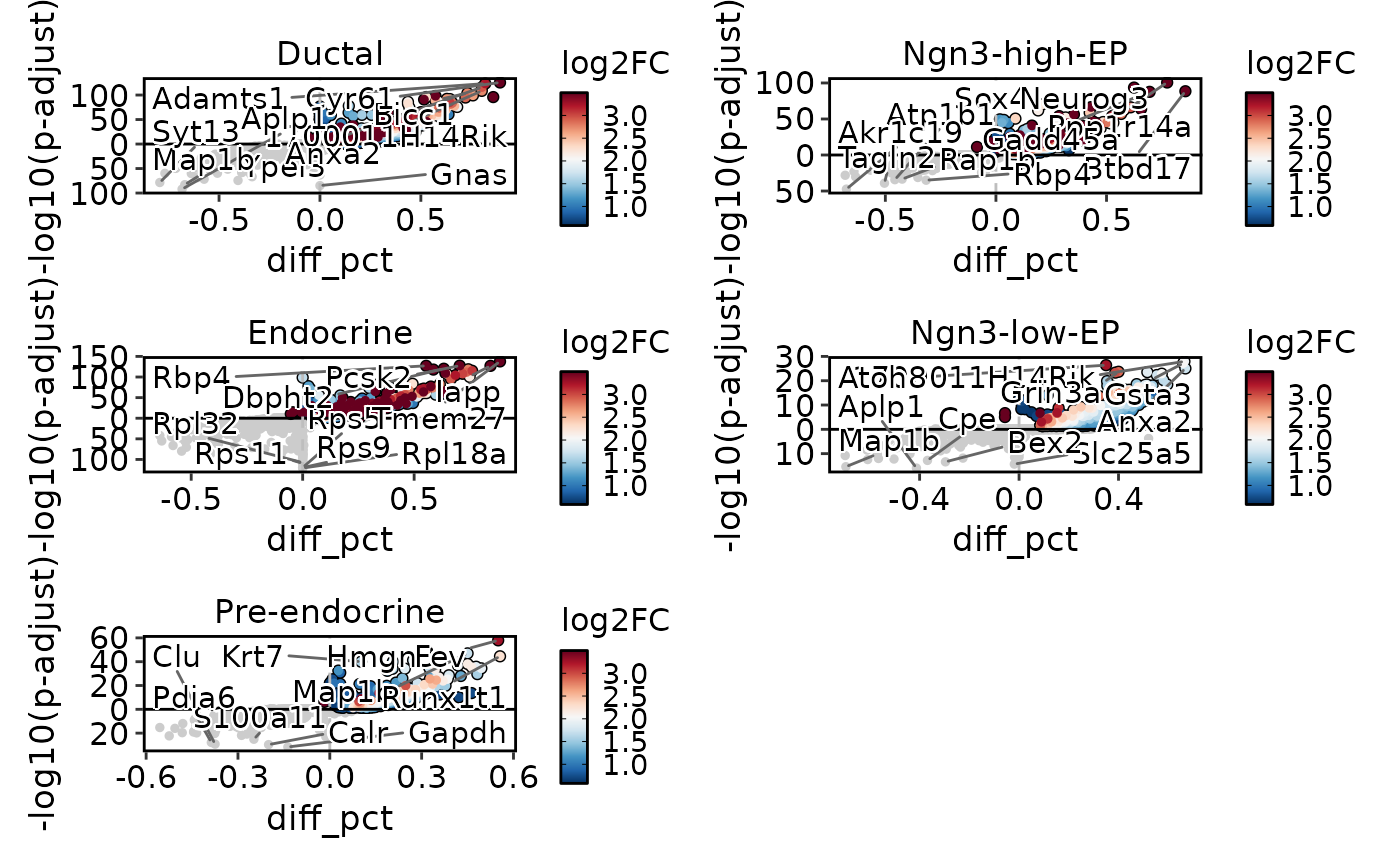 de_results1 <- pancreas_sub@tools$DEtest_CellType$AllMarkers_wilcox
DEtestPlot(
res = de_results1,
plot_type = "volcano",
ncol = 2
)
de_results1 <- pancreas_sub@tools$DEtest_CellType$AllMarkers_wilcox
DEtestPlot(
res = de_results1,
plot_type = "volcano",
ncol = 2
)
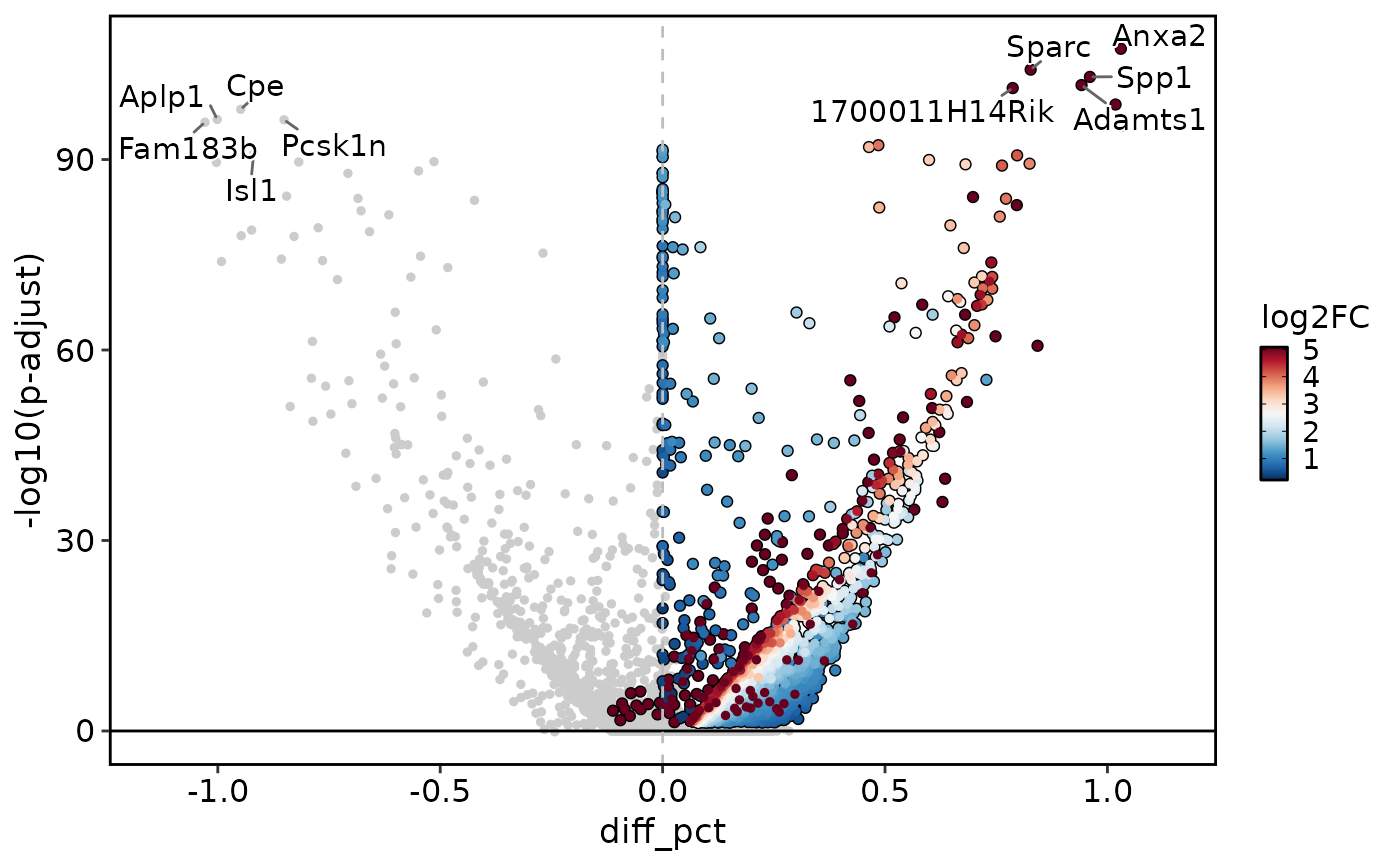 de_results2 <- Seurat::FindMarkers(
pancreas_sub,
group.by = "CellType",
ident.1 = "Ductal",
ident.2 = "Endocrine"
)
DEtestPlot(
res = de_results2,
plot_type = "volcano"
)
de_results2 <- Seurat::FindMarkers(
pancreas_sub,
group.by = "CellType",
ident.1 = "Ductal",
ident.2 = "Endocrine"
)
DEtestPlot(
res = de_results2,
plot_type = "volcano"
)
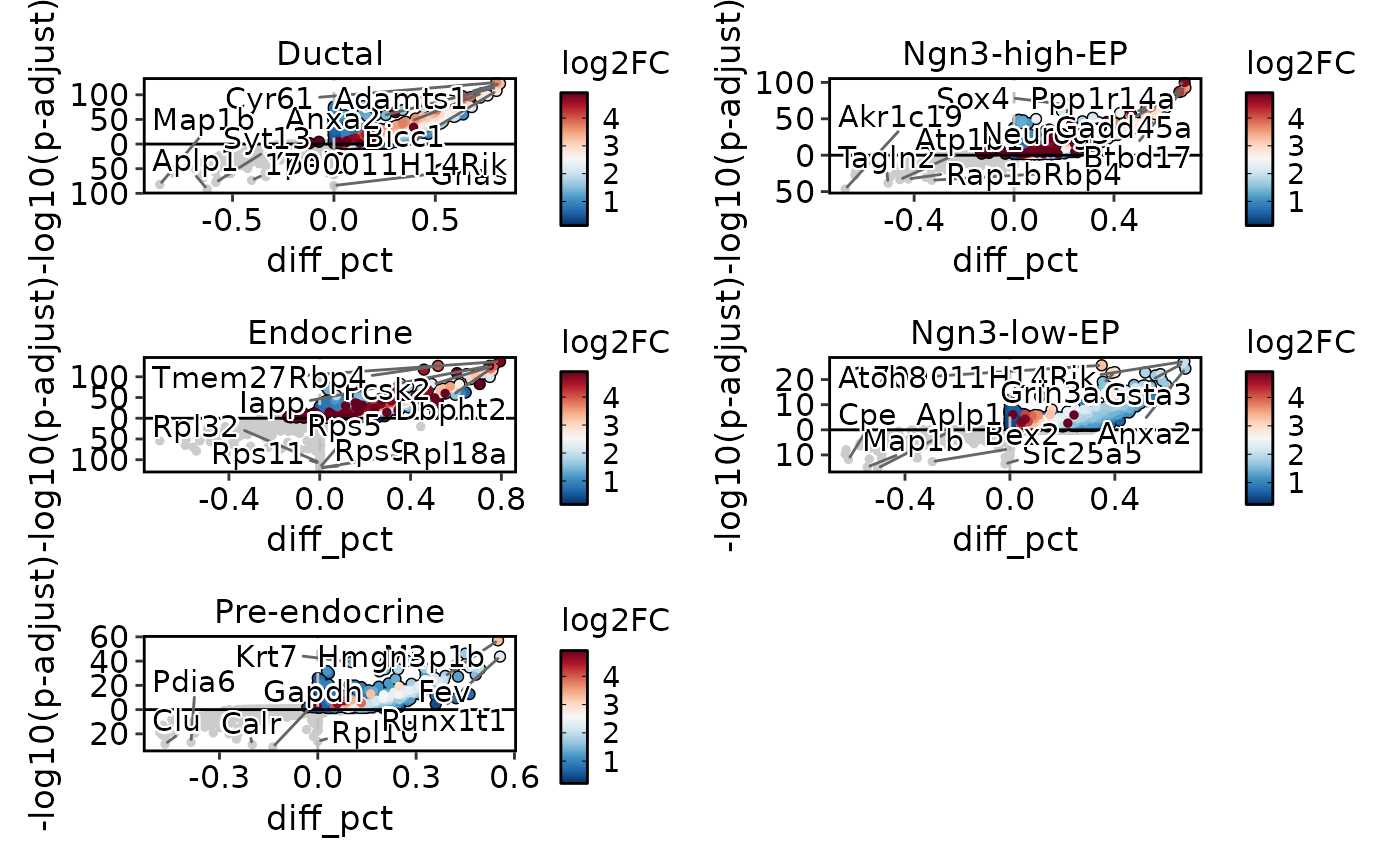 de_results3 <- Seurat::FindAllMarkers(
pancreas_sub,
group.by = "CellType"
)
#> Calculating cluster Ductal
#> Calculating cluster Ngn3-high-EP
#> Calculating cluster Endocrine
#> Calculating cluster Ngn3-low-EP
#> Calculating cluster Pre-endocrine
DEtestPlot(
res = de_results3,
plot_type = "volcano",
ncol = 2
)
de_results3 <- Seurat::FindAllMarkers(
pancreas_sub,
group.by = "CellType"
)
#> Calculating cluster Ductal
#> Calculating cluster Ngn3-high-EP
#> Calculating cluster Endocrine
#> Calculating cluster Ngn3-low-EP
#> Calculating cluster Pre-endocrine
DEtestPlot(
res = de_results3,
plot_type = "volcano",
ncol = 2
)